LSM Tree原理详解¶
1 前言¶
对于存储介质为磁盘或 SSD 的数据库,长期以来主流使用 B+ 树这种索引结构来实现快速数据查找。当数据量不太大时, B+ 树读写性能表现非常好。但是在海量数据情况下, B+ 树越来越高,由于 B+ 树更新和删除数据时需要沿着 B+ 树逐层进行页分裂和页合并,严重影响数据写入性能。为了应对这种情况, google 在论文《 Bigtable: A Distributed Storage System for Structured Data 》中介绍了一种新的数据组织结构 LSM Tree(Log-Structured Merge Tree) ,随后, Bigtable 主要作者 Jeffrey Dean 和 Sanjay Ghemawat 开源了一款基于 LSM Tree 实现的数据库 LevelDB ,让大家对 LSM Tree 的思想和实现理解得更为透彻、深入。当前,比较流行的 NoSQL 数据库,如 Cassandra 、 RocksDB 、 HBase 、 LevelDB 等, newSQL 数据库,如 TiDB ,均是使用 LSM Tree 来组织磁盘数据的。甚至像 SQLite 这种传统的关系型数据库和 MongoDB 这种传统的文档型数据库都提供了基于 LSM Tree 的存储引擎作为可选的存储引擎。
2 基本原理简述¶
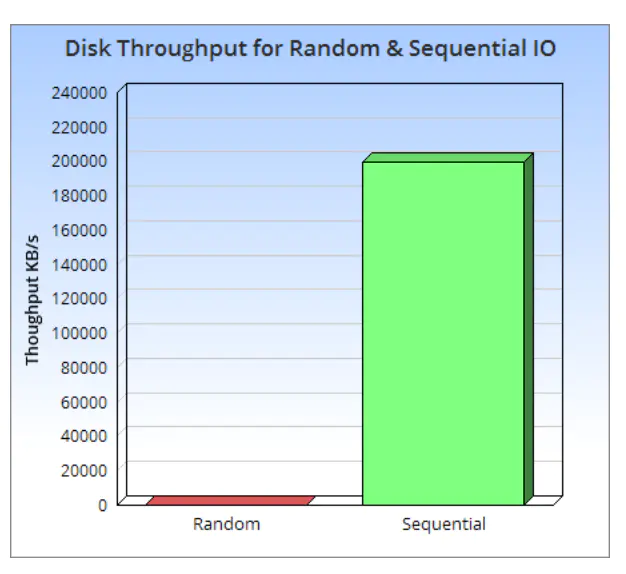
LSM Tree 的全称为 Log-Structured Merge Tree ,是一个分层、有序、针对块存储设备(机械硬盘和 SSD )特点而设计的数据存储结构。它的核心理论基础还是磁盘的顺序写速度比随机写速度快非常多,即使是 SSD ,由于块擦除和垃圾回收的影响,顺序写速度还是比随机写速度快很多。
LSM Tree 将存储数据切分为一系列的 SSTable ( Sorted String Table ),一个 SSTable 内的数据是有序的任意字节组(即 arbitrary byte string ,并不是指编程语言中的 String 字符串),而且, SSTable 一但写入磁盘中,就像日志一样不能再修改(这就是 Log-Structured Merge Tree 名字中 Log-Structured 一词的由来)。当要修改现有数据时, LSM Tree 并不直接修改旧数据,而是直接将新数据写入新的 SSTable 中。同样的,删除数据时, LSM Tree 也不直接删除旧数据,而是写一个相应数据的删除标记的记录到一个新的 SSTable 中。这样一来, LSM Tree 写数据时对磁盘的操作都是顺序块写入操作,而没有随机写操作。
LSM Tree 这种独特的写入方式,导致在查找数据时, LSM Tree 就不能像 B+ 树那样在一个统一的索引表中进行查找,而是从最新的 SSTable 到老的 SSTable 依次进行查找。如果在新 SSTable 中找到了需查找的数据或相应的删除标记,则直接返回查找结果;如果没有找到,再到老的 SSTable 中进行查找,直到最老的 SSTable 查找完。为了提高查找效率, LSM Tree 对 SSTable 进行分层、有序组织,也就是说把 SSTable 组织成多层,同一层可以有多个 SSTable ,同一个数据在同一层的多个 SSTable 中可以不重复,而且数据可以做到在同一层中是有序的,即每一个 SSTable 内的数据是有序的,前一个 SSTable 的最大数据值小于后一个 SSTable 的最小数据值(实际情况比这个复杂,后面会介绍)。这样可以加快在同一层 SSTable 中的数据查询速度。同时, LSM Tree 会将多个 SSTable 合并( Compact )为一个新的 SSTable ,这样可以减少 SSTable 的数量,同时把修改前的数据或删除的数据真正从 SSTable 中删除,减小了 SSTable 的大小(这就是 Log-Structured Merge Tree 名字中 Merge 一词的由来),对提高查找性能极其重要( SSTable 合并( Compact )过程对 LSM Tree 查找如此重要,以至于把它作为名字的一部分)。
3 读写过程详述¶
3.1 LSM Tree框架图¶
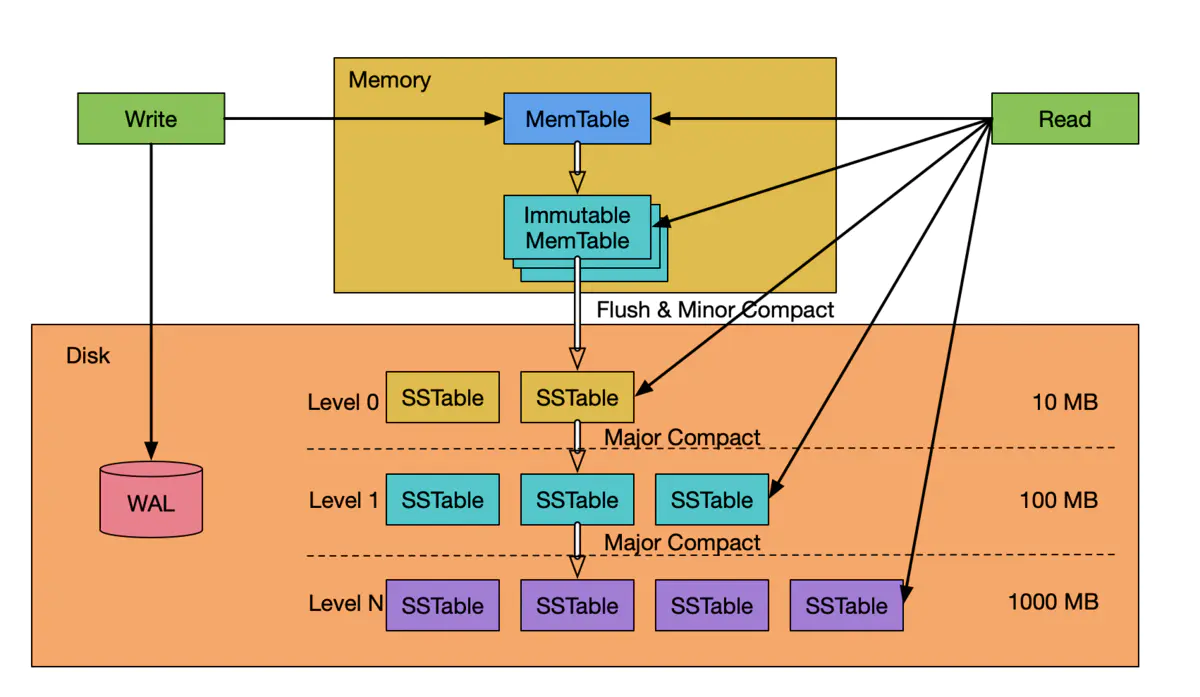
上图中, WAL ( Write Ahead LOG )严格来说本身并不是 LSM Tree 数据结构的一部分,但是实际系统中, WAL 是数据库不可或缺的一部分,把 WAL 包括进来才能更准确的理解 LSM Tree 。
从图中可知, LSM Tree 的数据由两部分组成:内存部分和持久到磁盘中的部分。内存部分由一个 MemTable 和一个或多个 Immutable MemTable 组成。磁盘中的部分由分布在多个 level 的 SSTable 组成。 level 级数越小( level 0 )表示处于该 level 的 SSTable 越新, level 级数越大( level 1...level N )表示处于该 level 的 SSTable 越老,最大级数( level N )大小由系统设定。在本图中,磁盘中最小的级数为 level 0 ,也有的系统把内存中的 Immutable MemTable 定义为 level 0 ,而磁盘中的数据从 Level 1 开始,这只是 level 定义的不同,并不影响系统的工作流程和对系统的理解。
WAL 的结构和作用跟其他数据库一样,是一个只能在尾部以 Append Only 方式追加记录的日志结构文件,它用来当系统崩溃重启时重放操作,使 MemTable和Immutable MemTable 中未持久化到磁盘中的数据不会丢失。
MemTable 往往是一个跳表( Skip List )组织的有序数据结构(当然,也可以是有序数组或红黑树等二叉搜索树),跳表既支持高效的动态插入数据,对数据进行排序,也支持高效的对数据进行精确查找和范围查找。
SSTable 一般由一组数据 block 和一组元数据 block 组成。元数据 block 存储了 SSTable 数据 block 的描述信息,如索引、 BloomFilter 、压缩、统计等信息。因为 SSTable 是不可更改的,且是有序的,索引往往采用二分法数组结构就可以了。为了节省存储空间和提升数据块 block 的读写效率,可以对数据 block 进行压缩。 RocksDB 的 SSTable ( sstfile )结构如下所示:
| Bash | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
论文《 BigTable 》对 SSTable 的描述我觉得是比较清晰的,现摘录如下,供大家参考:
Tip
An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk.
3.2 数据写入过程¶
如上图所示, LSM Tree 写入数据时,先写一条记录到 WAL 中,然后将数据写入内存中的 MemTable 中,这样写入操作就完成了。
写 MemTable 时,写入新的数据,与修改现有数据的部分字段以及修改现有数据的所有字段,写入操作过程几乎是一样的,都是把传入的数据(合并)写入到 MemTable 中。删除数据时,则是在 MemTable 中写入一条删除标记。当 MemTable 的大小达到设定的大小(典型值是 64KB )时, LSM Tree 会把当前 MemTable 冻结为一个不可修改的 Immutable MemTable ,然后创建一个新的 MemTable 供新的数据写入。同时, LSM Tree 一般会有一些与写入线程(或进程)相独立的背景线程(或进程)负责将 Immutable MemTable flush 到磁盘中,将数据持久化。已经 flush 到磁盘中的 Immutable MemTable 对应的 WAL 就可以从磁盘中删除了。而内存中 Immutable MemTable 数量的多少处决于 Immutable MemTable flush 的速度与 Immutable MemTable 生成的速度(数据写入速度)的差值
从 LSM Tree 数据写入过程可知, LSM Tree 数据写入的操作非常简单,过程也非常少,只要写 WAL 和内存中的 MemTable 即可。而写 WAL 是以在文件末尾追加记录方式的顺序写,无需操作任何数据结构,写入速度非常快。写 MemTable 虽然也需要进行跳表的插入和排序操作,但是 MemTable 是一个内存数据结构,同时 MemTable 的大小控制在一个非常非常小的规模(比如 64KB ),所以写 MemTable 也是一个非常非常快的过程。
同时,我们还可以看到,数据的写入速度与数据库中数据总量的多少没有关系。而且,不管是写入新的数据,还是全量修改或部分修改现有数据,或是删除现有数据, LSM Tree 的写入速度也几乎没多大差别。也就是说, LSM Tree 的写入速度是稳定的,跟数据规模和数据更新类型都没有关系。
3.3 数据查找过程根据¶
LSM Tree 的写入特点我们知道,如果一项数据更新多次,这项数据可能会存储在多个不同的 SSTable 中,甚至一项数据的不同部分的最新数据内容存储在不同的 SSTable 中(数据部分更新的场景)。 LSM Tree 把这种现象叫做空间放大( space amplification ),因为一项数据在磁盘中存储了多份副本,而老的副本是已经过时了的,不需要的,数据实际占用的存储空间比有效数据需要的大。
空间放大这种现象导致 LSM Tree 的查找过程是这样的:按新到老的顺序查找 SSTable ,直到在某个(或某些个) SSTable 中查找到了所需的数据,或者最老的 SSTable 查找完也没有找到需要的数据。具体查找顺序为:先在内存 MemTable 中查找,然后在内存中的 Immutable MemTable 中查找,然后在 level 0 SSTable 中查找,最后在 level N SSTable 中查找。
查找某个具体的 SSTable 时,一般先把 SSTable 的元数据 block 读到内存中,根据 BloomFilter 可以快速确定数据在当前 SSTable 中是否存在,如果存在,则采用二分法确定数据在哪个数据 block ,然后将相应数据 block 读到内存中进行精确查找。
从 LSM Tree 数据查找过程我们可以看到,为了查找到目标数据,我们需要读取并查找不包含目标数据的 SSTable ,如果目标数据在最底层 level N 的 SSTable 中,我们需要读取和查找所有的 SSTable ! LSM Tree 把这种读取和查找了无关 SSTable 的现象叫做读放大( read amplification )。
读放大现象严重影响了 LSM Tree 数据查找性能,甚至是灾难性的(数据压根不存在或在最老的 SSTable 中),论文《BigTable》提到了几种提升数据查找性能的方法:
-
压缩(
Compression)介绍
SSTable时已经提到了,对数据block进行压缩,通过增加占用CPU压缩和解压缩资源来降低数据block磁盘空间占用和读写时间。 -
BloomFilter描述查找过程时也已经提到了,
BloomFilter可以快速确定数据不在SSTable中,而不用读取数据block内容 -
缓存(
Cache)因为
SSTable是不可变的,非常适合缓存到内存中,这样热点数据不用访问磁盘 -
SSTable合并(Compaction)将多个
SSTable合并为一个SSTable,删除旧数据或物理删除已经被删除的数据,降低空间放大;同时减少SSTable数量,降低读放大
其实这些优化措施,除了 SSTable 合并是 LSM Tree 独有的,前面三条都是数据库通用的措施,甚至 SSTable 合并也不是 LSM Tree 独有的,它与更早出现的 lucene 的段合并( Segment Merge )的原理和目标其实是有相似的地方的(当然他们的写入和查找过程还是有本质区别的)。下面详细介绍下 SSTable 合并
4 SSTable合并¶
从上述读写过程描述可以看到, LSM Tree 虽然数据写入速度非常快,但是存在空间放大和读放大的现象,这些现象如果不进行抑制,可能导致读性能的极端恶化和空间占用过于膨胀,最终导致 LSM Tree 在实际生产环境中不可用。 SSTable 合并就是用来缓解这种现象的。 LSM Tree 支持将多个 SSTable 合并为一个新的 SSTable ,合并过程中,会删除旧的重叠数据,并真正物理删除被删除的数据,也减少了 SSTable 的数量,这样消除了空间放大,同时也提升了数据查找的性能。但是,合并需要将合并涉及的 SSTable 读入内存,并把合并后产生的新的 SSTable 写入磁盘,会增加磁盘 IO 和 CPU 的消耗,这种写入磁盘的数据量大于实际数据量现象成为写放大( write amplification ),当然合并也意味着读放大。由此可见, SSTable 合并是一把双刃剑,有利也有弊,需要合理利用。
SSTable 合并分为 minor compaction 和 major compaction , minor compaction 是指将内存中的 Immutable MemTable 内容 flush 到磁盘中形成 SSTable 时进行的数据处理过程。 major compaction 则是指相邻的两级 level 将数字小 level (如 level 0 )的 SSTable 合并入数字大 level (如 level 1 )的 SSTable 中的过程。
SSTable 合并其实就是在空间放大、写放大、读放大几个相互制约的因素间寻求平衡,不同的应用场景需要重点优化解决某个问题,从而形成了几种典型的 SSTable 合并策略:
4.1 leveled compaction¶
leveled compaction 为每层 level 的 SSTable 数据总大小设置一个阈值, level 数越大,阈值设置的也越大,比如 level0 阈值为 10MB 、 level1 阈值设置为 100MB 、 level2 阈值设置为 1000MB 。当某 level 层的数据总量大小超过设置的阈值时,则选取一个 SSTable 合并入高一级 level 层的一个或多个 SSTable 中。高 level 层涉及的 SSTable 的选择处决于数据的分布,以合并后高 level 层中的所有 SSTable 数据是整体有序的为准( one sorted run ),也就是说数据在同一层中不存在重叠的现象。
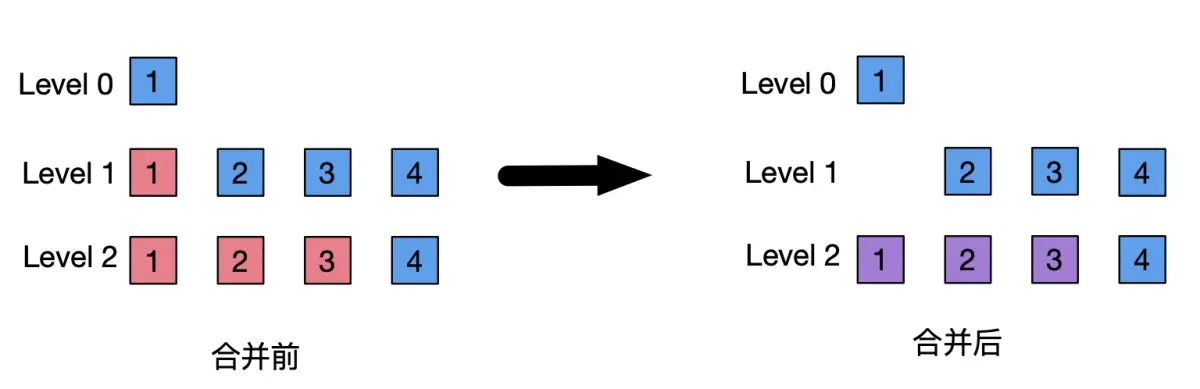
leveled compaction 因为会将 SSTable 合并入多个 SSTable 中,能保证同一层的 SSTable 中数据不会重叠,所以是一种最小化空间放大的策略。但是,合并时需要读取多个 SSTable ,然后写入多个更新后的 SSTable ,导致更大的写放大和读放大。但是在数据查找过程中,由于减少了需要查找 SSTable 的数量,降低了数据查找时的读放大,提升了数据查找的性能。所以, leveled compaction 适合比较关注数据查询速度和控制磁盘空间占用的场景。比如,数据写入一次,但是会被频繁反复查询;数据经常被修改,但是需要控制磁盘空间大小和保证数据查询速度。
Cassandra 的 LCS ( Leveled Compaction Strategy )和 RocksDB 的 Classic Leveled Compaction 采用的就是 leveled compaction 策略。
4.2 tiered compaction¶
tiered compaction 当某 level 层的 SSTable 数量达到设定的阈值时,则将该层的多个 SSTable 合并为一个新的 SSTable ,并放入高一层 level 中。
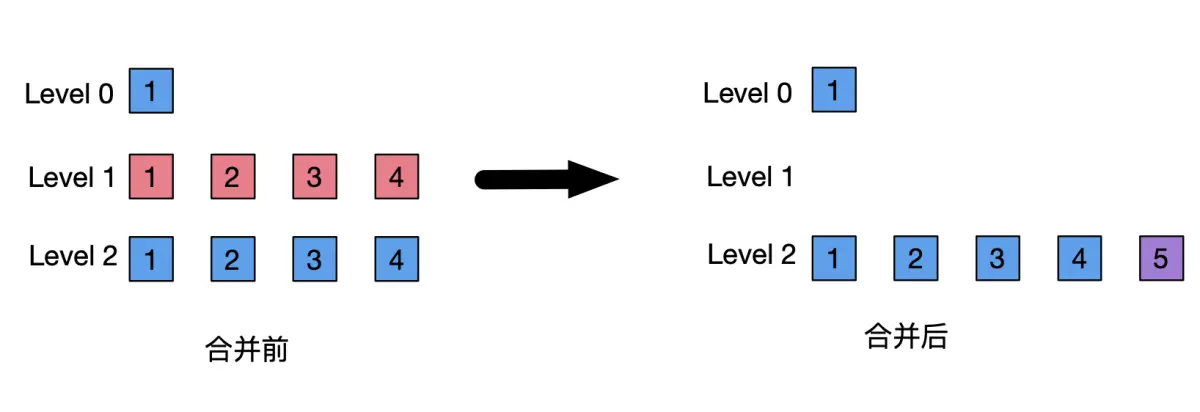
tiered compaction 比较偏重于控制写放大在一定程度的前提下降低空间放大和提升数据查询性能。但是在同一层的 SSTable 中还是存在数据重叠,数据查询性能不如 leveled compaction 。尤其是随着 level 数越来越大,单个 SSTable 数据量也越来越大,合并触发条件也越来越难,这些巨型 SSTable 中的重叠数据和被删除的数据占用的空间也就越来越难被释放掉。 tiered compaction 比较适合数据修改频率不高,且最近写入的数据查询频率比较高的场景。
Cassandra 的 STCS ( Size Tiered Compaction Strategy )和 RocksDB 的 universal Compaction 使用的是 tiered compaction 策略。
4.3 leveled-tiered mixed compaction¶
结合 leveled compaction 和 tiered compaction 的优势,在部分 level 之间采用 tiered compaction ,在另一部分 level 之间采用 leveled compaction 。
RocksDB 的 leveled Compaction 采用的是 leveled-tiered mixed compaction 策略。数据从 Immutable MemTable flush 到 level 0 时采用的是 tiered compaction ,也就是说 level0 中是存在重叠数据的。 level0 到 levelN 之间采用 leveld compaction 策略。
4.4 FIFO compaction¶
FIFO compaction 在磁盘中只有一个 level 层级, SSTable 按生成的时间顺序排列,删除过早生成的 SSTable 。
FIFO compaction 适合时间序列数据,一旦生成数据就不会再修改。
Cassandra 的 TWCS ( Time Window Compaction Strategy )、 DTCS ( Date Tiered Compaction Strategy )和 RocksDB 的 FIFO compaction 使用的是 FIFO 类型的合并策略。
5 LSM Tree原理对系统读写性能提升的几点启示¶
-
写数据时尽量批量操作。
LSM Tree数据写入性能已经很高了,但是批量操作时可以节省网络传输RTT时间。 -
将数据进行分片。这样多个分片可以并行写,如果数据路由处理得当,也可以提升数据查询速度。但是增加了维护多个分片数据读写的复杂度。
-
选择合适的主键。两个比较流行的选择是:
-
采用递增的数字作为主键;
-
采用业务本身标识符作为主键。数字作为主键可以减少写入和查询时进行比较、排序等操作的时间,还能提升索引缓存的效率;递增的数字往往保证是顺序写入的,可以减少排序时间。但是递增的数字往往不具备业务语义,业务实际查询时需要先查二级索引,然后进行主键查找。业务标识符往往是业务实际的身份区分符号,业务也往往通过业务标识符进行数据查询。但是业务标识符往往是一个字符串,可能会比较长,这样比较、排序、缓存效率方面不如数字。一般情况下,本人建议
LSM Tree数据库采用业务标识符作为主键。因为为业务标识符建立索引以及维护索引的成本是免不了的,与其建立二级索引,不如直接建立主键索引。
-
-
设计合理的二级索引,不建立不需要的二级索引。二级索引可以提升相应数据的查询速度,每增加一个二级索引,就需要额外维护相应的二级索引文件,严重影响写入数据性能。
-
根据具体场景使用合适的
SSTable合并策略。单次写,频繁读场景选择leveled compaction策略。 -
在允许情况下关闭自动
SSTable合并,在业务量低的时间段强制执行SSTable合并。 -
数据更新时合理选择全量更新(覆盖写)方式还是部分更新(增量写)方式。全量更新方式增加了传输和写入的数据量,但是可以提升数据查询速度。部分更新方式会使数据分布在多个
SSTable中,需要查询和合并多个SSTable中的数据才能得到完整的数据,会降低数据查询速度。如果数据修改比较频繁,且需要较高查询速度,建议采用全量更新方式。