2.2 基于 Arrow Flight SQL 的高速数据传输链路
Doris 基于 Arrow Flight SQL 协议实现了高速数据链路,支持多种语言使用 SQL 从 Doris 高速读取大批量数据。
1 用途
从 Doris 加载大批量数据到其他组件,如 Python/Java/Spark/Flink ,可以使用基于 Arrow Flight SQL 的 ADBC/JDBC 替代过去的 JDBC/PyMySQL/Pandas 来获得更高的读取性能,这在数据科学、数据湖分析等场景中经常遇到。
Apache Arrow Flight SQL 是一个由 Apache Arrow 社区开发的与数据库系统交互的协议,用于 ADBC 客户端使用 Arrow 数据格式与实现了 Arrow Flight SQL 协议的数据库交互,具有 Arrow Flight 的速度优势以及 JDBC/ODBC 的易用性。
Doris 支持 Arrow Flight SQL 的动机、设计与实现、性能测试结果、以及有关 Arrow Flight 、 ADBC 的更多概念可以看 GitHub Issue ,这篇文档主要介绍 Doris Arrow Flight SQL 的使用方法,以及一些常见问题。
安装 Apache Arrow 你可以去官方文档( Apache Arrow )找到详细的安装教程。
2 Python 使用方法
使用 Python 的 ADBC Driver 连接 Doris 实现数据的极速读取,下面的步骤使用 Python (版本 >= 3.9 )的 ADBC Driver 执行一系列常见的数据库语法操作,包括 DDL 、 DML 、设置 Session 变量以及 Show 语句等。
2.1 安装 Library
Library 被发布在 PyPI ,可通过以下方式简单安装:
| Bash |
|---|
| pip install adbc_driver_manager
pip install adbc_driver_flightsql
|
在代码中 import 以下模块、库来使用已安装的 Library :
| Python |
|---|
| import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
>>> print(adbc_driver_manager.__version__)
1.1.0
>>> print(adbc_driver_flightsql.__version__)
1.1.0
|
2.2 连接 Doris
创建与 Doris Arrow Flight SQL 服务交互的客户端。需提供 Doris FE 的 Host 、 Arrow Flight Port 、登陆用户名以及密码,并进行以下配置。修改 Doris FE 和 BE 的配置参数:
Tip
注: fe.conf 与 be.conf 中配置的 arrow_flight_sql_port 不相同
假设 Doris 实例中 FE 和 BE 的 Arrow Flight SQL 服务将分别在端口 9090 和 9091 上运行,且 Doris 用户名、密码为 "user" 、 "pass" ,那么连接过程如下所示:
| Python |
|---|
| conn = flight_sql.connect(uri="grpc://{FE_HOST}:{fe.conf:arrow_flight_sql_port}", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()
|
连接完成后,可以通过 SQL 使返回的 Cursor 与 Doris 交互,执行例如建表、获取元数据、导入数据、查询等操作。
2.3 建表与获取元数据
将 Query 传递给 cursor.execute() 函数,执行建表与获取元数据操作:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())
|
如果 StatusResult 返回 0 ,则说明 Query 执行成功(这样设计的原因是为了兼容 JDBC )。
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...
|
2.4 导入数据
执行 INSERT INTO ,向所创建表中导入少量测试数据:
| Python |
|---|
| cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
|
如下所示则证明导入成功:
如果需要导入大批量数据到 Doris ,可以使用 pydoris 执行 Stream Load 来实现。
2.5 执行查询
接着对上面导入的表进行查询查询,包括聚合、排序、 Set Session Variable 等操作。
| Python |
|---|
| cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())
|
结果如下所示:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]
|
2.6 完整代码
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61 | # Doris Arrow Flight SQL Test
# step 1, library is released on PyPI and can be easily installed.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# step 2, create a client that interacts with the Doris Arrow Flight SQL service.
# Modify arrow_flight_sql_port in fe/conf/fe.conf to an available port, such as 9090.
# Modify arrow_flight_sql_port in be/conf/be.conf to an available port, such as 9091.
conn = flight_sql.connect(uri="grpc://{FE_HOST}:{fe.conf:arrow_flight_sql_port}", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# interacting with Doris via SQL using Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# step3, execute DDL statements, create database/table, show stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# step4, insert into
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# step5, execute queries, aggregation, sort, set session variable
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# step6, close cursor
cursor.close()
|
3 JDBC Connector with Arrow Flight SQL
Arrow Flight SQL 协议的开源 JDBC 驱动兼容标准的 JDBC API ,可用于大多数 BI 工具通过 JDBC 访问 Doris ,并支持高速传输 Apache Arrow 数据。使用方法与通过 MySQL 协议的 JDBC 驱动连接 Doris 类似,只需将链接 URL 中的 jdbc:mysql 协议换成 jdbc:arrow-flight-sql 协议,查询返回的结果依然是 JDBC 的 ResultSet 数据结构。
3.1 POM dependency
| XML |
|---|
| <properties>
<arrow.version>15.0.1</arrow.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.arrow</groupId>
<artifactId>flight-sql-jdbc-core</artifactId>
<version>${arrow.version}</version>
</dependency>
</dependencies>
|
使用 Java 9 或更高版本时,必须通过在 Java 命令中添加 --add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED 来暴露某些 JDK 内部结构:
| Bash |
|---|
| # Directly on the command line
$ java --add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED -jar ...
# Indirectly via environment variables
$ env _JAVA_OPTIONS="--add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED" java -jar ...
|
否则,您可能会看到一些错误,如 module java.base does not "opens java.nio" to unnamed module 或者 module java.base does not "opens java.nio" to org.apache.arrow.memory.core 或者 ava.lang.NoClassDefFoundError: Could not initialize class org.apache.arrow.memory.util.MemoryUtil (Internal; Prepare)
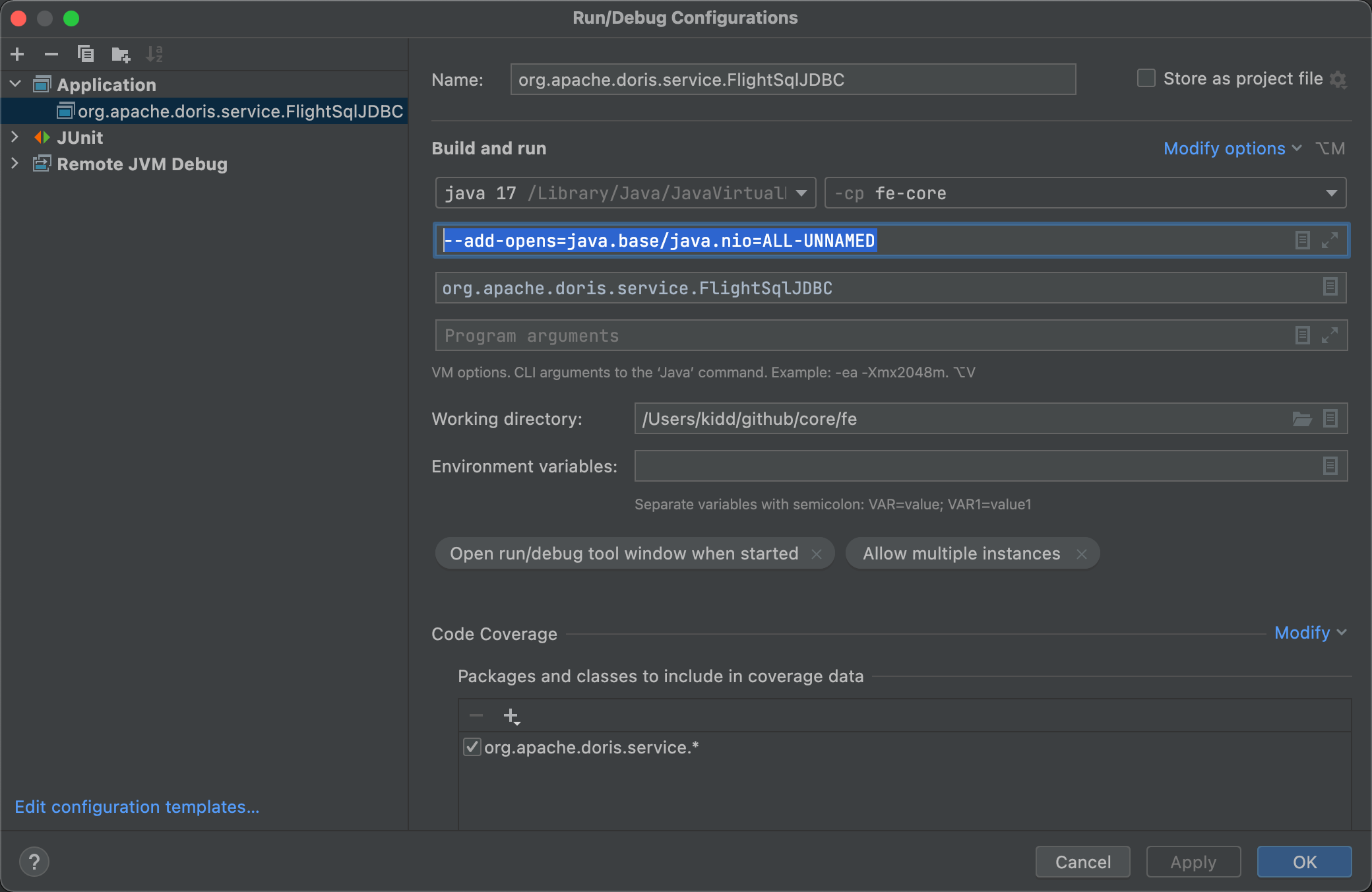
如果您在 IntelliJ IDEA 中调试,需要在 Run/Debug Configurations 的 Build and run 中增加 --add-opens=java.base/java.nio=ALL-UNNAMED ,参照下面的图片:
连接代码示例如下:
| Java |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://{FE_HOST}:{fe.conf:arrow_flight_sql_port}?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("select * from information_schema.tables;");
while (resultSet.next()) {
System.out.println(resultSet.toString());
}
resultSet.close();
stmt.close();
conn.close();
|
4 Java 使用方法
除了使用 JDBC ,与 Python 类似, Java 也可以创建 Driver 读取 Doris 并返回 Arrow 格式的数据,下面分别是使用 AdbcDriver 和 JdbcDriver 连接 Doris Arrow Flight Server 。
4.1 POM dependency
| XML |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | <properties>
<adbc.version>0.12.0</adbc.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-driver-jdbc</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-core</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-driver-manager</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-sql</artifactId>
<version>${adbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.arrow.adbc</groupId>
<artifactId>adbc-driver-flight-sql</artifactId>
<version>${adbc.version}</version>
</dependency>
</dependencies>
|
4.2 ADBC Driver
连接代码示例如下:
| Java |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | // 1. new driver
final BufferAllocator allocator = new RootAllocator();
FlightSqlDriver driver = new FlightSqlDriver(allocator);
Map<String, Object> parameters = new HashMap<>();
AdbcDriver.PARAM_URI.set(parameters, Location.forGrpcInsecure("{FE_HOST}", {fe.conf:arrow_flight_sql_port}).getUri().toString());
AdbcDriver.PARAM_USERNAME.set(parameters, "root");
AdbcDriver.PARAM_PASSWORD.set(parameters, "");
AdbcDatabase adbcDatabase = driver.open(parameters);
// 2. new connection
AdbcConnection connection = adbcDatabase.connect();
AdbcStatement stmt = connection.createStatement();
// 3. execute query
stmt.setSqlQuery("select * from information_schema.tables;");
QueryResult queryResult = stmt.executeQuery();
ArrowReader reader = queryResult.getReader();
// 4. load result
List<String> result = new ArrayList<>();
while (reader.loadNextBatch()) {
VectorSchemaRoot root = reader.getVectorSchemaRoot();
String tsvString = root.contentToTSVString();
result.add(tsvString);
}
System.out.printf("batchs %d\n", result.size());
// 5. close
reader.close();
queryResult.close();
stmt.close();
connection.close();
|
4.3 JDBC Driver
连接代码示例如下:
| Java |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | final Map<String, Object> parameters = new HashMap<>();
AdbcDriver.PARAM_URI.set(
parameters,"jdbc:arrow-flight-sql://{FE_HOST}:{fe.conf:arrow_flight_sql_port}?useServerPrepStmts=false&cachePrepStmts=true&useSSL=false&useEncryption=false");
AdbcDriver.PARAM_USERNAME.set(parameters, "root");
AdbcDriver.PARAM_PASSWORD.set(parameters, "");
try (
BufferAllocator allocator = new RootAllocator();
AdbcDatabase db = new JdbcDriver(allocator).open(parameters);
AdbcConnection connection = db.connect();
AdbcStatement stmt = connection.createStatement()
) {
stmt.setSqlQuery("select * from information_schema.tables;");
AdbcStatement.QueryResult queryResult = stmt.executeQuery();
ArrowReader reader = queryResult.getReader();
List<String> result = new ArrayList<>();
while (reader.loadNextBatch()) {
VectorSchemaRoot root = reader.getVectorSchemaRoot();
String tsvString = root.contentToTSVString();
result.add(tsvString);
}
long etime = System.currentTimeMillis();
System.out.printf("batchs %d\n", result.size());
reader.close();
queryResult.close();
stmt.close();
} catch (Exception e) {
e.printStackTrace();
}
|
4.4 JDBC 和 Java 连接方式的选择
对比传统的 jdbc:mysql 连接方式, Jdbc 和 Java 的 Arrow Flight SQL 连接方式的性能测试见 GitHub Issue ,这里基于测试结论给出一些使用建议。
-
上述三种 Java Arrow Flight SQL 连接方式的选择上,如果后续的数据分析将基于行存的数据格式,那么使用 jdbc:arrow-flight-sql ,这将返回 JDBC ResultSet 格式的数据;如果后续的数据分析可以基于 Arrow 格式或其他列存数据格式,那么使用 Flight AdbcDriver 或 Flight JdbcDriver 直接返回 Arrow 格式的数据,这将避免行列转换,并可利用 Arrow 的特性加速数据解析。
-
无论解析 JDBC ResultSet 还是 Arrow 格式的数据,所耗费的时间都大于读取数据的耗时,如果你那里使用 Arrow Flight SQL 的性能不符合预期,和 jdbc:mysql:// 相比提升有限,不妨分析下是否解析数据耗时太长。
-
对所有连接方式而言, JDK 17 都比 JDK 1.8 读取数据的速度更快。
-
当读取数据量非常大时,使用 Arrow Flight SQL 将比 jdbc:mysql:// 使用更少的内存,所以如果你受内存不足困扰,同样可以尝试下 Arrow Flight SQL 。
-
除了上述三种连接方式,还可以使用原生的 FlightClient 连接 Arrow Flight Server ,可以更加灵活的并行读取多个 Endpoints 。 Flight AdbcDriver 也是基于 FlightClient 创建的链接,相较于直接使用 FlightClient 更简单。
5 与其他大数据组件交互
5.1 Spark & Flink
Arrow Flight 官方目前没有支持 Spark 和 Flink 的计划(见 GitHub Issue ),Doris Spark Connector和 Doris Flink Connector 目前还不支持通过 Arrow Flight SQL 访问 Doris 。其中 Doris Flink Connector 支持 Arrow Flight SQL 正在开发中,预期能提升数倍读取性能。
社区之前参考开源的 Spark-Flight-Connector ),在 Spark 中使用 FlightClient 连接 Doris 测试,发现 Arrow 与 Doris Block 之间数据格式转换的速度更快,是 CSV 格式与 Doris Block 之间转换速度的 10 倍,而且对 Map , Array 等复杂类型的支持更好,这是因为 Arrow 数据格式的压缩率高,传输时网络开销小。不过目前 Doris Arrow Flight 还没有实现多节点并行读取,仍是将查询结果汇总到一台 BE 节点后返回,对简单的批量导出数据而言,性能可能没有 Doris Spark Connector 快,后者支持 Tablet 级别的并行读取。如果你希望在 Spark 使用 Arrow Flight SQL 连接 Doris ,可以参考开源的 Spark-Flight-Connector 和 Dremio-Flight-Connector 自行实现。
6 FAQ
-
ARM 环境报错 get flight info statement failed, arrow flight schema timeout, TimeoutException: Waited 5000 milliseconds for io.grpc.stub.Client ,如果 Linux 内核版本 <= 4.19.90 ,需要升级到 4.19.279 及以上,或者在低版本 Linux 内核的环境中重新编译 Doris BE
问题原因:这是因为老版本 Linux 内核和 Arrow 存在兼容性问题, cpp: arrow::RecordBatch::MakeEmpty() 构造 Arrow Record Batch 时会卡住,导致 Doris BE 的 Arrow Flight Server 在 5000ms 内没有回应 Doris FE 的 Arrow Flight Server 的 RPC 请求,导致 FE 给 Client 返回 rpc timeout failed 。 Spark 和 Flink 读取 Doris 时也是将查询结果转换成 Arrow Record Batch 后返回,所以也存在同样的问题。
kylinv10 SP2 和 SP3 的 Linux 内核版本最高只有 4.19.90-24.4.v2101.ky10.aarch64 ,无法继续升级内核版本,只能在 kylinv10 上重新编译 Doris BE ,如果使用新版本 ldb_toolchain 编译 Doris BE 后问题依然存在,可以尝试使用低版本 ldb_toolchain v0.17 编译,如果你的 ARM 环境无法连外网,华为云提供 ARM + kylinv10 ,阿里云提供 x86 + kylinv10
-
目前 jdbc:arrow-flight-sql 和 Java ADBC/JDBCDriver 不支持 prepared statement 传递参数,类似 select * from xxx where id=? ,将报错 parameter ordinal 1 out of range ,这是 Arrow Flight SQL 的一个 BUG(GitHub Issue)
-
修改 jdbc:arrow-flight-sql 每次读取的批次大小,在某些场景下可以提升性能,通过修改 org.apache.arrow.adbc.driver.jdbc.JdbcArrowReader 文件中 makeJdbcConfig 方法中的 setTargetBatchSize ,默认是 1024 ,然后将修改后的文件保存到本地同名路径目录下,从而覆盖原文件生效。
-
ADBC v0.10,JDBC 和 Java ADBC/JDBCDriver 还不支持并行读取,没有实现 stmt.executePartitioned() 这个方法,只能使用原生的 FlightClient 实现并行读取多个 Endpoints ,使用方法 sqlClient=new FlightSqlClient, execute=sqlClient.execute(sql), endpoints=execute.getEndpoints(), for(FlightEndpoint endpoint: endpoints) ,此外, ADBC V0.10 默认的 AdbcStatement 实际是 JdbcStatement , executeQuery 后将行存格式的 JDBC ResultSet 又重新转成的 Arrow 列存格式,预期到 ADBC 1.0.0 时 Java ADBC 将功能完善 GitHub Issue 。
-
截止 Arrow v15.0,Arrow JDBC Connector 不支持在 URL 中指定 database name ,比如 jdbc:arrow-flight-sql://{FE_HOST}:{fe.conf:arrow_flight_sql_port}/test?useServerPrepStmts=false 中指定连接 test database 无效,只能手动执行 SQL use database 。
-
Doris 2.1.4 version 存在一个 Bug ,读取大数据量时有几率报错,在 Fix arrow flight result sink #36827 这个 pr 修复,升级 Doris 2.1.5 version 可以解决。问题详情见: Questions
-
Warning: Cannot disable autocommit; conn will not be DB-API 2.0 compliant 使用 Python 时忽略这个 Warning ,这是 Python ADBC Client 的问题,这不会影响查询。
-
Python 报错 grpc: received message larger than max (20748753 vs. 16777216) ,参考 Python: grpc: received message larger than max (20748753 vs. 16777216) #2078 在 Database Option 中增加 adbc_driver_flightsql.DatabaseOptions.WITH_MAX_MSG_SIZE.value 。
-
Doris version 2.1.7 版本之前,报错 Reach limit of connections ,这是因为没有限制单个用户的 Arrow Flight 连接数小于 UserProperty 中的 max_user_connections ,默认 100 ,可以通过 SET PROPERTY FOR 'Billie' 'max_user_connections' = '1000'; 修改 Billie 用户的当前最大连接数到 100 ,或者在 fe.conf 中增加 arrow_flight_token_cache_size=50 来限制整体的 Arrow Flight 连接数。 Doris version 2.1.7 版本之前 Arrow Flight 连接默认 3 天超时断开,只强制连接数小于 qe_max_connection/2 ,超过时依据 lru 淘汰, qe_max_connection 是 fe 所有用户的总连接数,默认 1024 。具体可以看 arrow_flight_token_cache_size 这个 conf 的介绍。在 Fix exceed user property max connection cause Reach limit of connections #39127 修复,问题详情见: Questions