4.1.2.6 Group Commit¶
Group Commit 不是一种新的导入方式,而是对 INSERT INTO tbl VALUES(...),Stream Load,Http Stream 的扩展,大幅提升了高并发小写入的性能。您的应用程序可以直接使用 JDBC 将数据高频写入 Doris ,同时通过使用 PreparedStatement 可以获得更高的性能。在日志场景下,您也可以利用 Stream Load 或者 Http Stream 将数据高频写入 Doris 。
1 Group Commit 模式¶
Group Commit 写入有三种模式,分别是:
-
关闭模式(
off_mode)不开启
Group Commit,保持以上三种导入方式的默认行为。 -
同步模式(
sync_mode)Doris根据负载和表的group_commit_interval属性将多个导入在一个事务提交,事务提交后导入返回。这适用于高并发写入场景,且在导入完成后要求数据立即可见。 -
异步模式(
async_mode)Doris首先将数据写入WAL(Write Ahead Log),然后导入立即返回。Doris会根据负载和表的group_commit_interval属性异步提交数据,提交之后数据可见。为了防止WAL占用较大的磁盘空间,单次导入数据量较大时,会自动切换为sync_mode。这适用于写入延迟敏感以及高频写入的场景。WAL的数量可以通过FE http接口查看,具体可见这里,也可以在BE的metrics中搜索关键词wal查看。
2 Group Commit 使用方式¶
假如表的结构为:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 | |
2.1 使用 JDBC¶
当用户使用 JDBC insert into values 方式写入时,为了减少 SQL 解析和生成规划的开销,我们在 FE 端支持了 MySQL 协议的 PreparedStatement 特性。当使用 PreparedStatement 时, SQL 和其导入规划将被缓存到 Session 级别的内存缓存中,后续的导入直接使用缓存对象,降低了 FE 的 CPU 压力。下面是在 JDBC 中使用 PreparedStatement 的例子:
-
设置
JDBC URL并在Server端开启Prepared StatementJava 1url = jdbc:mysql://127.0.0.1:9030/db?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500 -
配置
group_commit session变量,有如下两种方式:-
通过
JDBC url设置,增加sessionVariables=group_commit=async_modeJava 1url = jdbc:mysql://127.0.0.1:9030/db?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500&sessionVariables=group_commit=async_mode&sessionVariables=enable_nereids_planner=false -
通过执行
SQL设置Java 1 2 3
try (Statement statement = conn.createStatement()) { statement.execute("SET group_commit = async_mode;"); }
-
-
使用
PreparedStatementJava 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
private static final String JDBC_DRIVER = "com.mysql.jdbc.Driver"; private static final String URL_PATTERN = "jdbc:mysql://%s:%d/%s?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=500&sessionVariables=group_commit=async_mode&sessionVariables=enable_nereids_planner=false"; private static final String HOST = "127.0.0.1"; private static final int PORT = 9087; private static final String DB = "db"; private static final String TBL = "dt"; private static final String USER = "root"; private static final String PASSWD = ""; private static final int INSERT_BATCH_SIZE = 10; private static void groupCommitInsertBatch() throws Exception { Class.forName(JDBC_DRIVER); // add rewriteBatchedStatements=true and cachePrepStmts=true in JDBC url // set session variables by sessionVariables=group_commit=async_mode in JDBC url try (Connection conn = DriverManager.getConnection( String.format(URL_PATTERN, HOST, PORT, DB), USER, PASSWD)) { String query = "insert into " + TBL + " values(?, ?, ?)"; try (PreparedStatement stmt = conn.prepareStatement(query)) { for (int j = 0; j < 5; j++) { // 10 rows per insert for (int i = 0; i < INSERT_BATCH_SIZE; i++) { stmt.setInt(1, i); stmt.setString(2, "name" + i); stmt.setInt(3, i + 10); stmt.addBatch(); } int[] result = stmt.executeBatch(); } } } catch (Exception e) { e.printStackTrace(); } }
Warning
由于高频的 insert into 语句会打印大量的 audit log ,对最终性能有一定影响,默认关闭了打印 prepared 语句的 audit log 。可以通过设置 session variable 的方式控制是否打印 prepared 语句的 audit log 。
| SQL | |
|---|---|
1 2 3 | |
关于 JDBC 的更多用法,参考使用 Insert 方式同步数据。
2.2 使用Golang进行Group Commit¶
Golang 的 prepared 语句支持有限,所以我们可以通过手动客户端攒批的方式提高 Group Commit 的性能,以下为一个示例程序。
| Go | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 | |
2.3 INSERT INTO VALUES¶
-
异步模式
SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
# 配置 session 变量开启 group commit (默认为 off_mode),开启异步模式 mysql> set group_commit = async_mode; # 这里返回的 label 是 group_commit 开头的,可以区分出是否使用了 group commit mysql> insert into dt values(1, 'Bob', 90), (2, 'Alice', 99); Query OK, 2 rows affected (0.05 sec) {'label':'group_commit_a145ce07f1c972fc-bd2c54597052a9ad', 'status':'PREPARE', 'txnId':'181508'} # 可以看出这个 label, txn_id 和上一个相同,说明是攒到了同一个导入任务中 mysql> insert into dt(id, name) values(3, 'John'); Query OK, 1 row affected (0.01 sec) {'label':'group_commit_a145ce07f1c972fc-bd2c54597052a9ad', 'status':'PREPARE', 'txnId':'181508'} # 不能立刻查询到 mysql> select * from dt; Empty set (0.01 sec) # 10 秒后可以查询到,可以通过表属性 group_commit_interval 控制数据可见延迟 mysql> select * from dt; +------+-------+-------+ | id | name | score | +------+-------+-------+ | 1 | Bob | 90 | | 2 | Alice | 99 | | 3 | John | NULL | +------+-------+-------+ 3 rows in set (0.02 sec) -
同步模式
SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
# 配置 session 变量开启 group commit (默认为 off_mode),开启同步模式 mysql> set group_commit = sync_mode; # 这里返回的 label 是 group_commit 开头的,可以区分出是否谁用了 group commit,导入耗时至少是表属性 group_commit_interval mysql> insert into dt values(4, 'Bob', 90), (5, 'Alice', 99); Query OK, 2 rows affected (10.06 sec) {'label':'group_commit_d84ab96c09b60587_ec455a33cb0e9e87', 'status':'PREPARE', 'txnId':'3007', 'query_id':'fc6b94085d704a94-a69bfc9a202e66e2'} # 数据可以立刻读出 mysql> select * from dt; +------+-------+-------+ | id | name | score | +------+-------+-------+ | 1 | Bob | 90 | | 2 | Alice | 99 | | 3 | John | NULL | | 4 | Bob | 90 | | 5 | Alice | 99 | +------+-------+-------+ 5 rows in set (0.03 sec) -
关闭模式
SQL 1mysql> set group_commit = off_mode;
2.4 Stream Load¶
假如 data.csv 的内容为:
| Text Only | |
|---|---|
1 2 | |
-
异步模式
Bash 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
# 导入时在 header 中增加"group_commit:async_mode"配置 curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:async_mode" -H "column_separator:," http://{fe_host}:{http_port}/api/db/dt/_stream_load { "TxnId": 7009, "Label": "group_commit_c84d2099208436ab_96e33fda01eddba8", "Comment": "", "GroupCommit": true, "Status": "Success", "Message": "OK", "NumberTotalRows": 2, "NumberLoadedRows": 2, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 19, "LoadTimeMs": 35, "StreamLoadPutTimeMs": 5, "ReadDataTimeMs": 0, "WriteDataTimeMs": 26 } # 返回的 GroupCommit 为 true,说明进入了 group commit 的流程 # 返回的 Label 是 group_commit 开头的,是真正消费数据的导入关联的 label -
同步模式
Bash 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
# 导入时在 header 中增加"group_commit:sync_mode"配置 curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:sync_mode" -H "column_separator:," http://{fe_host}:{http_port}/api/db/dt/_stream_load { "TxnId": 3009, "Label": "group_commit_d941bf17f6efcc80_ccf4afdde9881293", "Comment": "", "GroupCommit": true, "Status": "Success", "Message": "OK", "NumberTotalRows": 2, "NumberLoadedRows": 2, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 19, "LoadTimeMs": 10044, "StreamLoadPutTimeMs": 4, "ReadDataTimeMs": 0, "WriteDataTimeMs": 10038 } # 返回的 GroupCommit 为 true,说明进入了 group commit 的流程 # 返回的 Label 是 group_commit 开头的,是真正消费数据的导入关联的 label
关于 Stream Load 使用的更多详细语法及最佳实践,请参阅 Stream Load 。
2.5 Http Stream¶
-
异步模式
Bash 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
# 导入时在 header 中增加"group_commit:async_mode"配置 curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:async_mode" -H "sql:insert into db.dt select * from http_stream('column_separator'=',', 'format' = 'CSV')" http://{fe_host}:{http_port}/api/_http_stream { "TxnId": 7011, "Label": "group_commit_3b45c5750d5f15e5_703428e462e1ebb0", "Comment": "", "GroupCommit": true, "Status": "Success", "Message": "OK", "NumberTotalRows": 2, "NumberLoadedRows": 2, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 19, "LoadTimeMs": 65, "StreamLoadPutTimeMs": 41, "ReadDataTimeMs": 47, "WriteDataTimeMs": 23 } # 返回的 GroupCommit 为 true,说明进入了 group commit 的流程 # 返回的 Label 是 group_commit 开头的,是真正消费数据的导入关联的 label -
同步模式
Bash 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
# 导入时在 header 中增加"group_commit:sync_mode"配置 curl --location-trusted -u {user}:{passwd} -T data.csv -H "group_commit:sync_mode" -H "sql:insert into db.dt select * from http_stream('column_separator'=',', 'format' = 'CSV')" http://{fe_host}:{http_port}/api/_http_stream { "TxnId": 3011, "Label": "group_commit_fe470e6752aadbe6_a8f3ac328b02ea91", "Comment": "", "GroupCommit": true, "Status": "Success", "Message": "OK", "NumberTotalRows": 2, "NumberLoadedRows": 2, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 19, "LoadTimeMs": 10066, "StreamLoadPutTimeMs": 31, "ReadDataTimeMs": 32, "WriteDataTimeMs": 10034 } # 返回的 GroupCommit 为 true,说明进入了 group commit 的流程 # 返回的 Label 是 group_commit 开头的,是真正消费数据的导入关联的 label
关于 Http Stream 使用的更多详细语法及最佳实践,请参阅 Stream Load 。
3 自动提交条件¶
当满足时间间隔(默认为 10 秒)或数据量(默认为 64 MB )其中一个条件时,会自动提交数据。
3.1 修改提交间隔¶
默认提交间隔为 10 秒,用户可以通过修改表的配置调整:
| SQL | |
|---|---|
1 2 3 | |
3.2 修改提交数据量¶
Group Commit 的默认提交数据量为 64 MB ,用户可以通过修改表的配置调整:
| SQL | |
|---|---|
1 2 3 | |
4 使用限制¶
-
当开启了
Group Commit模式,系统会判断用户发起的INSERT INTO VALUES语句是否符合Group Commit的条件,如果符合,该语句的执行会进入到Group Commit写入中。符合以下条件会自动退化为非Group Commit方式:-
事务写入,即
Begin; INSERT INTO VALUES; COMMIT方式 -
指定
Label,即INSERT INTO dt WITH LABEL {label} VALUES -
VALUES中包含表达式,即INSERT INTO dt VALUES (1 + 100) -
列更新写入
-
表不支持
light schema change
-
-
当开启了
Group Commit模式,系统会判断用户发起的Stream Load和Http Stream是否符合Group Commit的条件,如果符合,该导入的执行会进入到Group Commit写入中。符合以下条件的会自动退化为非Group Commit方式:-
两阶段提交
-
指定
Label,即通过-H "label:my_label"设置 -
列更新写入
-
表不支持
light schema change
-
-
对于
Unique模型,由于Group Commit不能保证提交顺序,用户可以配合Sequence列使用来保证数据一致性 -
对
max_filter_ratio语义的支持-
在默认的导入中,
filter_ratio是导入完成后,通过失败的行数和总行数计算,决定是否提交本次写入 -
在
Group Commit模式下,由于多个用户发起的导入会被一个内部导入执行,虽然可以计算出每个导入的filter_ratio,但是数据一旦进入内部导入,就只能commit transaction -
Group Commit模式支持了一定程度的max_filter_ratio语义,当导入的总行数不高于group_commit_memory_rows_for_max_filter_ratio(配置在be.conf中,默认为10000行),max_filter_ratio工作
-
-
WAL限制-
对于
async_mode的Group Commit写入,会把数据写入WAL。如果内部导入成功,则WAL被立刻删除;如果内部导入失败,通过导入WAL的方法来恢复数据 -
目前
WAL文件只存储在一个BE上,如果这个BE磁盘损坏或文件误删等,可能导入丢失部分数据 -
当下线
BE节点时,请使用DECOMMISSION命令,安全下线节点,防止该节点下线前WAL文件还没有全部处理完成,导致部分数据丢失 -
对于
async_mode的Group Commit写入,为了保护磁盘空间,当遇到以下情况时,会切换成sync_mode-
导入数据量过大,即超过
WAL单目录的80%空间 -
不知道数据量的
chunked stream load -
导入数据量不大,但磁盘可用空间不足
-
-
当发生重量级
Schema Change(目前加减列、修改varchar长度和重命名列是轻量级Schema Change,其它的是重量级Schema Change)时,为了保证WAL能够适配表的Schema,在Schema Change最后的FE修改元数据阶段,会拒绝Group Commit写入,客户端收到insert table ${table_name} is blocked on schema change异常,客户端重试即可
-
5 相关系统配置¶
5.1 BE 配置¶
group_commit_wal_path
-
描述:
group commit存放WAL文件的目录 -
默认值:默认在用户配置的
storage_root_path的各个目录下创建一个名为wal的目录。配置示例:Bash 1group_commit_wal_path=/data1/storage/wal;/data2/storage/wal;/data3/storage/wal
group_commit_memory_rows_for_max_filter_ratio
-
描述:当
group commit导入的总行数不高于该值,max_filter_ratio正常工作,否则不工作 -
默认值:
10000
6 性能¶
我们分别测试了使用 Stream Load 和 JDBC 在高并发小数据量场景下 group commit (使用 async mode )的写入性能。
6.1 Stream Load 日志场景测试¶
-
机器配置
-
1台FE:阿里云8核CPU、16GB内存、1块100GB ESSD PL1云磁盘 -
3台BE:阿里云16核CPU、64GB内存、1块1TB ESSD PL1云磁盘 -
1台测试客户端:阿里云16核CPU、64GB内存、1块100GB ESSD PL1云磁盘 -
测试版本为
Doris-3.0.1
-
-
数据集
httplogs数据集,总共31GB、2.47亿条
-
测试工具
doris-streamloader
-
测试方法
- 导入
247249096行数据
- 导入
-
测试结果
导入方式 单并发数据量 并发数 耗时 (秒) 导入速率 (行/秒) 导入吞吐 (MB/秒) group_commit 10 KB 10 2204 112,181 14.8 group_commit 10 KB 30 2176 113,625 15.0 group_commit 100 KB 10 283 873,671 115.1 group_commit 100 KB 30 244 1,013,315 133.5 group_commit 500 KB 10 125 1,977,992 260.6 group_commit 500 KB 30 122 2,026,631 267.1 group_commit 1 MB 10 119 2,077,723 273.8 group_commit 1 MB 30 119 2,077,723 273.8 group_commit 10 MB 10 118 2,095,331 276.1 非group_commit 1 MB 10 1883 131,305 17.3 非group_commit 10 MB 10 294 840,983 105.4 非group_commit 10 MB 30 118 2,095,331 276.1
在上面的 group_commit 测试中, BE 的 CPU 使用率在 10-40% 之间。
可以看出, group_commit 模式在小数据量并发导入的场景下,能有效的提升导入性能,同时减少版本数,降低系统合并数据的压力。
6.2 JDBC¶
-
机器配置
-
1台FE:阿里云8核CPU、16GB内存、1块100GB ESSD PL1云磁盘 -
1台BE:阿里云16核CPU、64GB内存、1块500GB ESSD PL1云磁盘 -
1台测试客户端:阿里云16核CPU、64GB内存、1块100GB ESSD PL1云磁盘 -
测试版本为
Doris-3.0.1 -
关闭打印
parpared语句的audit log以提高性能
-
-
数据集
tpch sf10 lineitem表数据集,30个文件,总共约22 GB,1.8亿行
-
测试工具
DataX
-
测试方法
- 通过
txtfilereader向mysqlwriter写入数据,配置不同并发数和单个INSERT的行数
- 通过
-
测试结果
单个 insert 的行数 并发数 导入速率 (行/秒) 导入吞吐 (MB/秒) 100 10 160,758 17.21 100 20 210,476 22.19 100 30 214,323 22.92
在上面的测试中, FE 的 CPU 使用率在 60-70% 左右, BE 的 CPU 使用率在 10-20% 左右。
6.3 Insert into sync 模式小批量数据¶
-
机器配置
-
1台FE:阿里云16核CPU、64GB内存、1块500GB ESSD PL1云磁盘 -
5台BE:阿里云16核CPU、64GB内存、1块1TB ESSD PL1云磁盘。 -
1台测试客户端:阿里云16核CPU、64GB内存、1块100GB ESSD PL1云磁盘 -
测试版本为
Doris-3.0.1
-
-
数据集
-
tpch sf10 lineitem表数据集。 -
建表语句为
SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
CREATE TABLE IF NOT EXISTS lineitem ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) NOT NULL, L_LINESTATUS CHAR(1) NOT NULL, L_SHIPDATE DATE NOT NULL, L_COMMITDATE DATE NOT NULL, L_RECEIPTDATE DATE NOT NULL, L_SHIPINSTRUCT CHAR(25) NOT NULL, L_SHIPMODE CHAR(10) NOT NULL, L_COMMENT VARCHAR(44) NOT NULL ) DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER) DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 32 PROPERTIES ( "replication_num" = "3" );
-
-
测试工具
-
Jmeter需要设置的
jmeter参数如下图所示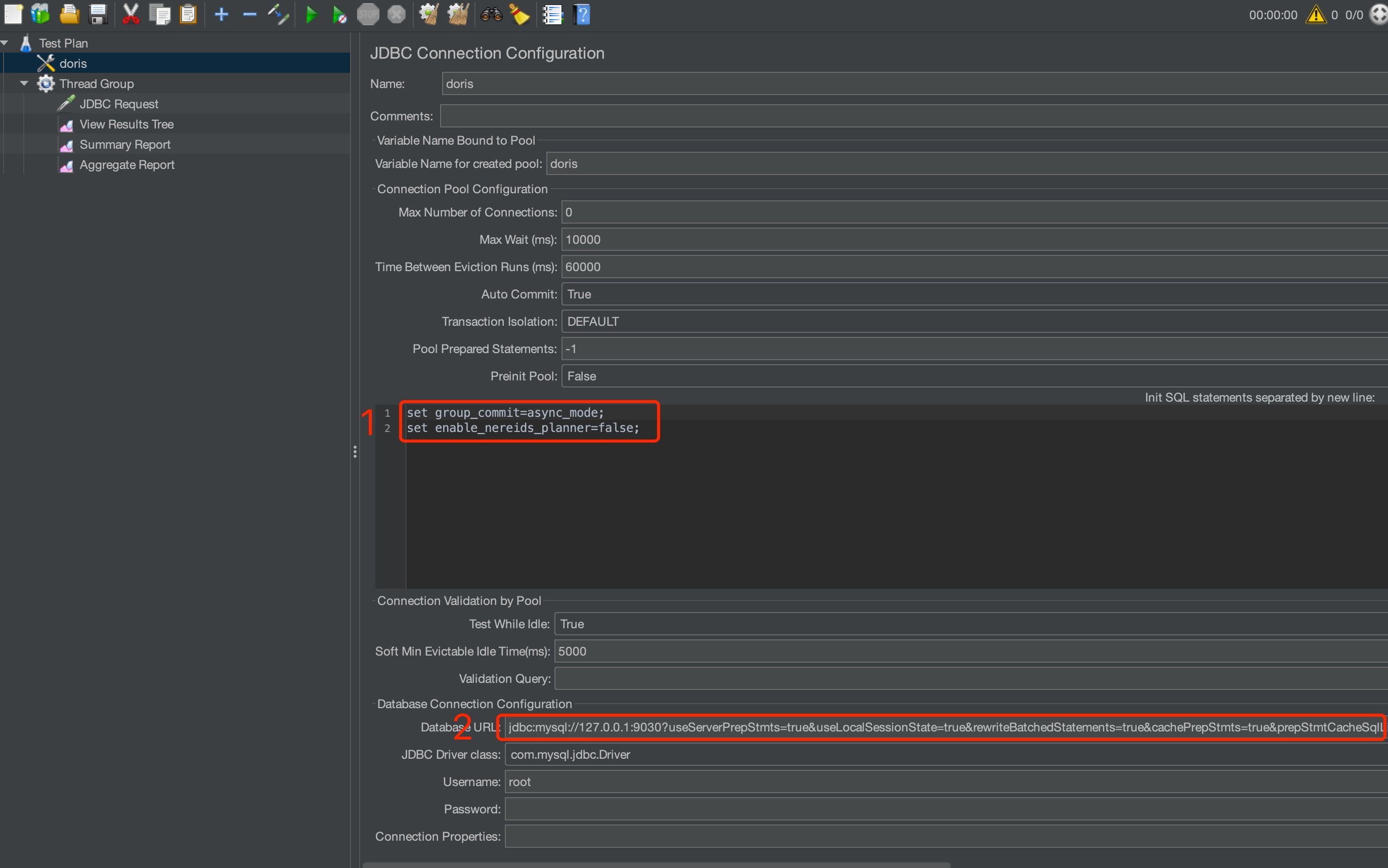
-
设置测试前的
init语句,set group_commit=async_mode以及set enable_nereids_planner=false。 -
开启
jdbc的prepared statement,完整的url为jdbc:mysql://127.0.0.1:9030?useServerPrepStmts=true&useLocalSessionState=true&rewriteBatchedStatements=true&cachePrepStmts=true&prepStmtCacheSqlLimit=99999&prepStmtCacheSize=50&sessionVariables=group_commit=async_mode&sessionVariables=enable_nereids_planner=false。 -
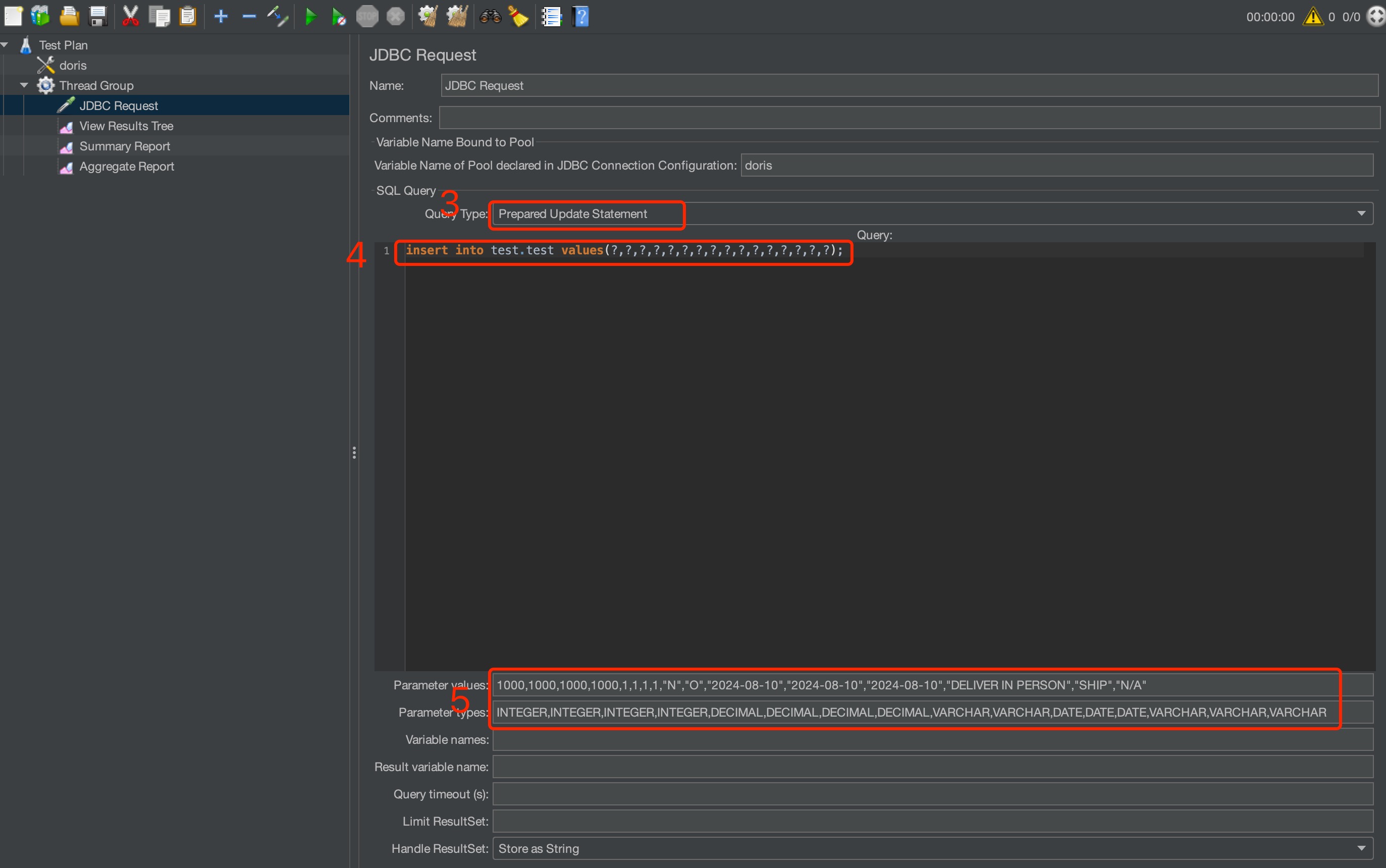
设置导入类型为
prepared update statement。 -
设置导入语句。
-
设置每次需要导入的值,注意,导入的值与导入值的类型要一一匹配。
-
-
-
测试方法
- 通过
Jmeter向Doris写数据。每个并发每次通过insert into写入1行数据。
- 通过
-
测试结果
-
数据单位为行每秒。
-
以下测试分为
30,100,500并发。30并发sync模式5个BE3副本性能测试Group commit internal 10ms 20ms 50ms 100ms enable_nereids_planner=true 891.8 701.1 400.0 237.5 enable_nereids_planner=false 885.8 688.1 398.7 232.9 100并发sync模式5个BE3副本性能测试Group commit internal 10ms 20ms 50ms 100ms enable_nereids_planner=true 2427.8 2068.9 1259.4 764.9 enable_nereids_planner=false 2320.4 1899.3 1206.2 749.7 500并发sync模式5个BE3副本性能测试Group commit internal 10ms 20ms 50ms 100ms enable_nereids_planner=true 5567.5 5713.2 4681.0 3131.2 enable_nereids_planner=false 4471.6 5042.5 4932.2 3641.1
-
6.4 Insert into sync 模式大批量数据¶
-
机器配置
-
1台FE:阿里云16核CPU、64GB内存、1块500GB ESSD PL1云磁盘 -
5台BE:阿里云16核CPU、64GB内存、1块1TB ESSD PL1云磁盘。注:测试中分别用了1台,3台,5台BE进行测试。 -
1台测试客户端:阿里云16核CPU、64GB内存、1块100GB ESSD PL1云磁盘 -
测试版本为
Doris-3.0.1
-
-
数据集
-
tpch sf10 lineitem表数据集。 -
建表语句为
SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
CREATE TABLE IF NOT EXISTS lineitem ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) NOT NULL, L_LINESTATUS CHAR(1) NOT NULL, L_SHIPDATE DATE NOT NULL, L_COMMITDATE DATE NOT NULL, L_RECEIPTDATE DATE NOT NULL, L_SHIPINSTRUCT CHAR(25) NOT NULL, L_SHIPMODE CHAR(10) NOT NULL, L_COMMENT VARCHAR(44) NOT NULL ) DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER) DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 32 PROPERTIES ( "replication_num" = "3" );
-
-
测试工具
Jmeter
-
测试方法
- 通过
Jmeter向Doris写数据。每个并发每次通过insert into写入1000行数据。
- 通过
-
测试结果
-
数据单位为行每秒。
-
以下测试分为
30,100,500并发。30并发sync模式5个BE3副本性能测试Group commit internal 10ms 20ms 50ms 100ms enable_nereids_planner=true 9.1K 11.1K 11.4K 11.1K enable_nereids_planner=false 157.8K 159.9K 154.1K 120.4K 100并发sync模式5个BE3副本性能测试Group commit internal 10ms 20ms 50ms 100ms enable_nereids_planner=true 10.0K 9.2K 8.9K 8.9K enable_nereids_planner=false 130.4k 131.0K 130.4K 124.1K 500并发sync模式5个BE3副本性能测试Group commit internal 10ms 20ms 50ms 100ms enable_nereids_planner=true 2.5K 2.5K 2.3K 2.1K enable_nereids_planner=false 94.2K 95.1K 94.4K 94.8K
-