4.1.7 从其他 AP 系统迁移数据¶
从其他 AP 系统迁移数据到 Doris ,可以有多种方式:
-
Hive/Iceberg/Hudi等,可以使用Multi-Catalog来映射为外表,然后使用Insert Into,来将数据导入 -
也可以从原来
AP系统中导出数据为CSV等数据格式,然后再将导出的数据导入到Doris -
可以使用
Spark / Flink系统,利用AP系统的Connector来读取数据,然后调用Doris Connector写入Doris
除此之外,还有以下第三方提供的迁移工具可供选择:
-
X2DorisX2Doris专门用于将各种离线数据迁移到Apache Doris中的核心工具,该工具集自动建Doris表和数据迁移为一体,目前支持了Apache Doris/Hive/Kudu/StarRocks数据库往Doris迁移的工作,整个过程可视化的平台操作,非常简单易用,减轻数据同步到Doris中的门槛。Note
这些第三方提供的工具并非由
Apache Doris维护或认可,这些工作由Committers和Doris PMC监督。使用这些资源和服务完全由您自行决定,社区不负责验证这些工具的许可或有效性。Note
如果有其他迁移工具可以加入此列表,可以联系 dev@doris.apache.org
1 X2Doris 核心特性¶
1.1 多源支持¶
定位于一站式数据迁移工具, X2Doris 目前已支持了 Apache Hive 、 Apache Kudu 、 StarRocks 以及 Apache Doris 自身作为数据源端, Greenplum 、 Druid 等更多数据源正在开发中,后续将陆续发布。其中 Hive 版本已支持 Hive 1.x 和 2.x 版本, Doris 、 StarRocks 、 Kudu 等数据源也同时支持了多个不同版本。
基于 X2Doris 用户可以构建从其他 OLAP 系统到 Apache Doris 的整库迁移链路,并可以实现不同 Doris 集群间的数据备份和恢复。
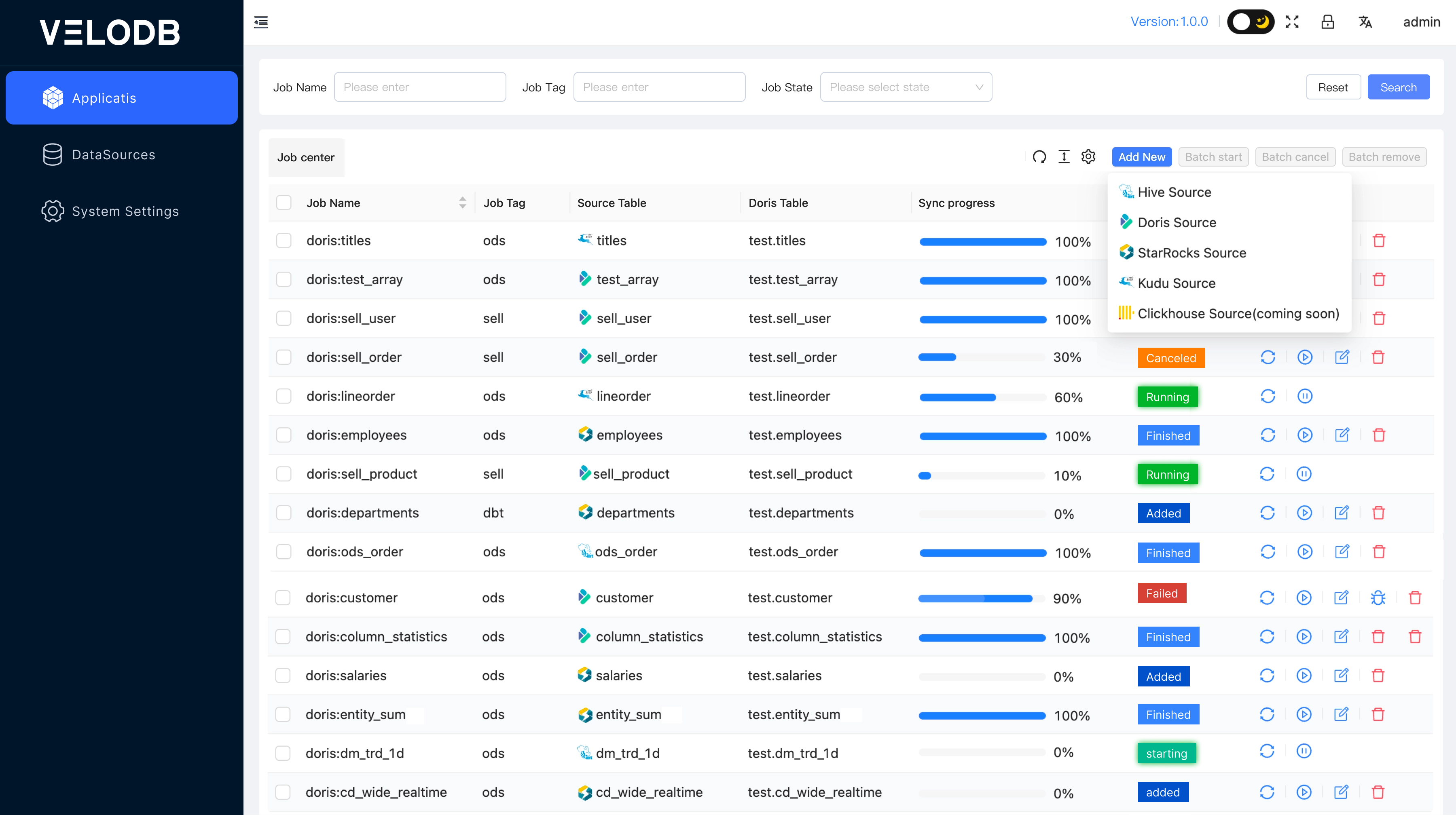
1.2 自动建表¶
数据迁移中最大的痛点,首当其冲的是如何将待迁移的源表在 Apache Doris 中创建对应的目标表。在实际业务场景中,存储在 Hive 中动辄上千张表,让用户手动创建目标表并转换对应的 DDL 语句效率显得过于低下,不具备实际操作可能性。
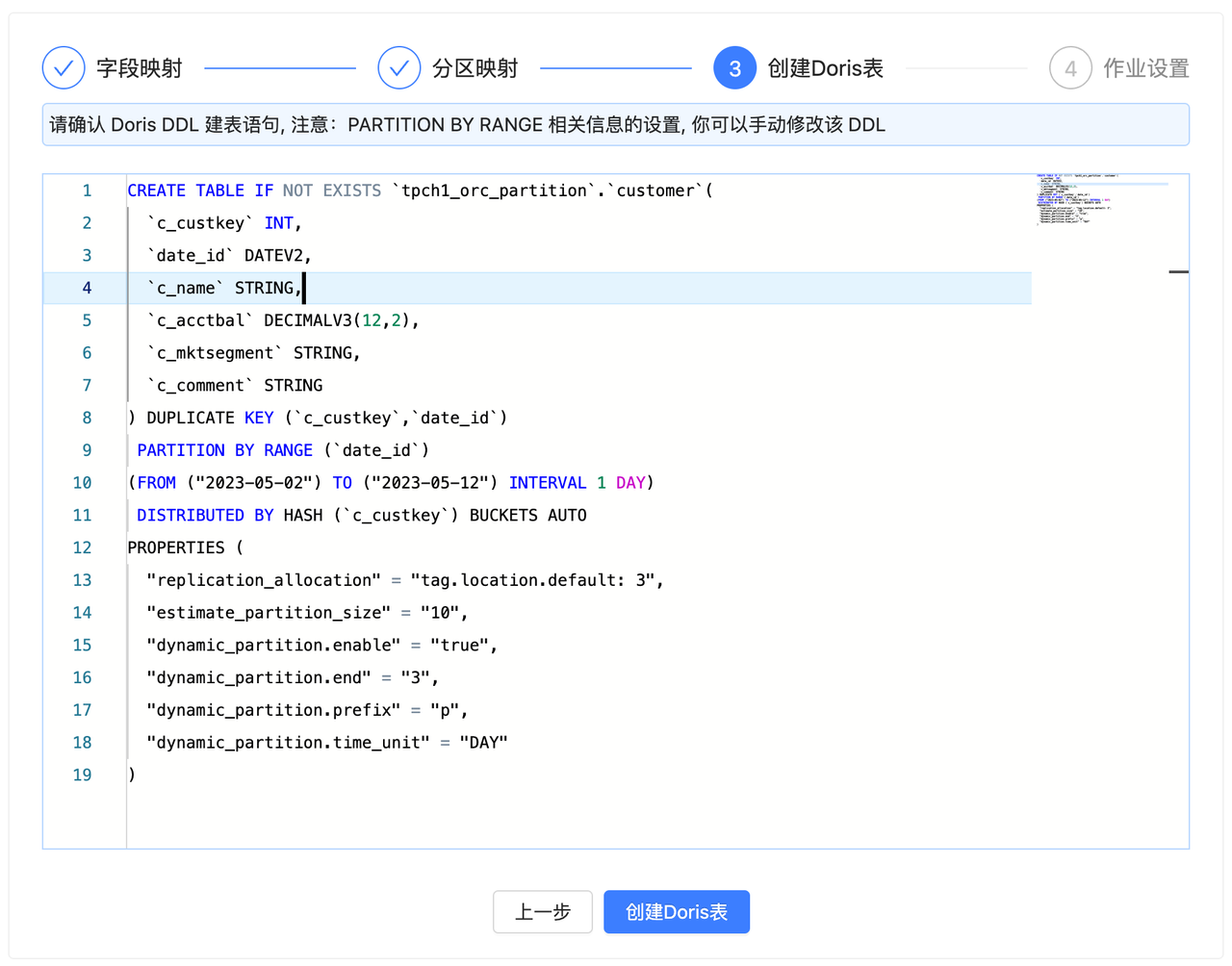
X2Doris 为此场景做了适配,在此以 Hive 表迁移为例。在迁移 Hive 表的时候, X2Doris 会在 Apache Doris 中自动创建 Duplicate Key 模型表(也可手动修改)并读取 Hive 表的元数据信息,通过字段名和字段类型自动识别分区字段,如果识别到分区则会提示进行分区映射,最后会直接生成对应的 Doris 目标表 DDL 。
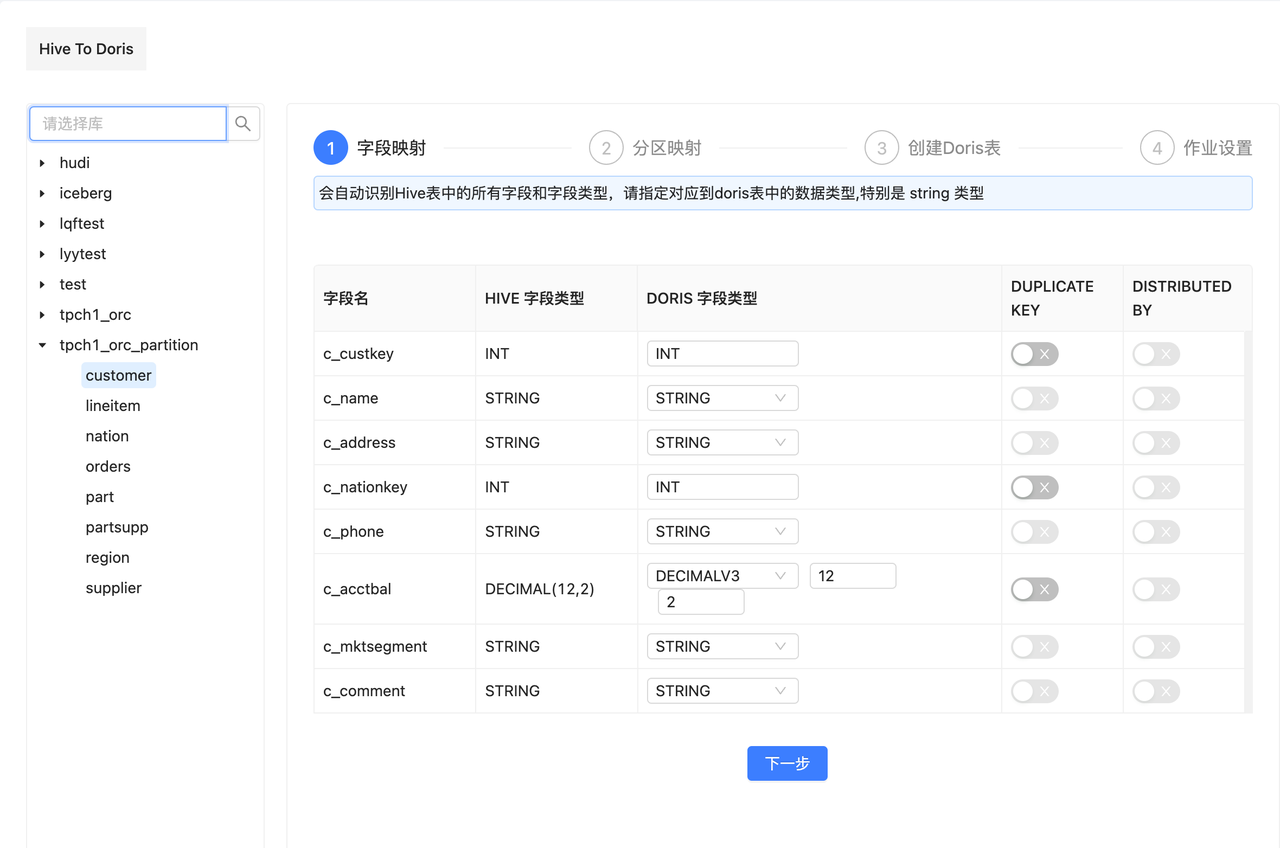
在上游数据源为 Doris/StarRocks 时, X2Doris 会自动根据源表信息解析出表模型,自动根据源表字段类型映射对应的目标字段类型,针对上游的 Properties 参数也会识别处理,转换成对应目标表的属性参数。除此以外, X2Doris 还对复杂类型进行了增强,实现了对 Array 、 Map 、 Bitmap 类型的数据迁移。
1.3 极速稳定¶
在数据写入方面, X2Doris 特别针对读取数据进行了优化。通过优化数据攒批逻辑进一步减小了内存的使用,同时对 Stream Load 写入请求进行了大量改进和增强,对内存使用和释放进行优化,进一步提升数据迁移的速度和稳定性。
对比其他同类型的迁移工具, X2Doris 性能约比同类工具快 2-10 倍。比如,在单机 1G 内存情况下,其他工具对 5000w 条数据进行全量数据同步,耗时约为 90s ,而 X2Doris 仅需 50s 不到、性能提升接近 100% 。
在一次实际大规模日志数据迁移场景中,单条数据 1KB 大小、单表数据接近 1 亿条、总存储空间约 90 GB ,基于 X2Doris 仅需 2 分钟即可完成全表迁移,平均写入速度近 800 MB/s 。