5.2 连接(JOIN)¶
1 什么是 JOIN¶
在关系型数据库中,数据被分布在多个表中,这些表之间通过特定关系相互关联。 SQL JOIN 操作允许我们根据这些关联条件将不同的表合并成一个更完整的结果集。
2 Doris 支持的 JOIN 类型¶
-
INNER JOIN(内连接):对左表每一行和右表所有行进行JOIN条件比较,返回两个表中满足JOIN条件的匹配行。详细信息请参考SELECT中有关于联接查询的语法定义 -
LEFT JOIN(左连接):在INNER JOIN的结果集基础上。如果左表的行在右表中没有匹配,则返回左表的所有行,同时右表对应的列显示为NULL。 -
RIGHT JOIN(右连接):与LEFT JOIN相反,如果右表的行在左表中没有匹配,则返回右表的所有行,同时左表对应的列显示为NULL。 -
FULL JOIN(全连接):在INNER JOIN的结果集基础上。返回两个表中所有的行,如果某行在另一侧表中没有 -
CROSS JOIN(交叉连接):没有JOIN条件,返回两个表的笛卡尔积,即左表的每一行与右表的每一行都进行组合。 -
LEFT SEMI JOIN(左半连接):对左表每一行和右表所有行进行JOIN条件比较,如果存在匹配,就返回左表的对应行。 -
RIGHT SEMI JOIN(右半连接):与LEFT SEMI JOIN相反,对右表每一行和左表所有行进行JOIN条件比较,如果存在匹配,就返回右表的对应行。 -
LEFT ANTI JOIN(左反半连接):对左表每一行和右表所有行进行JOIN条件比较,如果没有匹配,则返回左表的对应行。 -
RIGHT ANTI JOIN(右反半连接):与LEFT ANTI JOIN相反,对右表每一行和左表所有行进行JOIN条件比较,如果没有匹配,则返回这些行。 -
NULL AWARE LEFT ANTI JOIN(对NULL值特殊处理的左反半连接):与LEFT ANTI JOIN类似,但忽略左表中匹配列为NULL的行。
3 Doris 中的 JOIN 物理实现¶
Doris 支持两种 JOIN 的物理实现方式: Hash Join 和 Nest Loop Join 。
-
Hash Join:在右表上根据等值JOIN列构建一个哈希表,左表的数据以流式方式通过该哈希表进行JOIN计算。这种方法的局限性在于它仅适用于等值JOIN条件的情况。 -
Nest Loop Join:通过两层循环,以左表驱动,对左表的每一行逐一遍历右表的每一行,进行join条件判断。适用于所有JOIN场景,包括处理Hash Join无法胜任的情况,比如涉及大于或小于比较条件的查询,或是需要执行笛卡尔积运算的场景。但相比Hash Join,Nest Loop Join在性能上可能会有所不及。
4 Doris Hash Join 的实现方式¶
作为分布式 MPP 数据库, Apache Doris 在 Hash Join 过程中需要进行数据的 Shuffle ,进行拆分调度,以确保 JOIN 结果的正确性。以下是几种数据 Shuffle 方式:
4.1 Broadcast Join¶
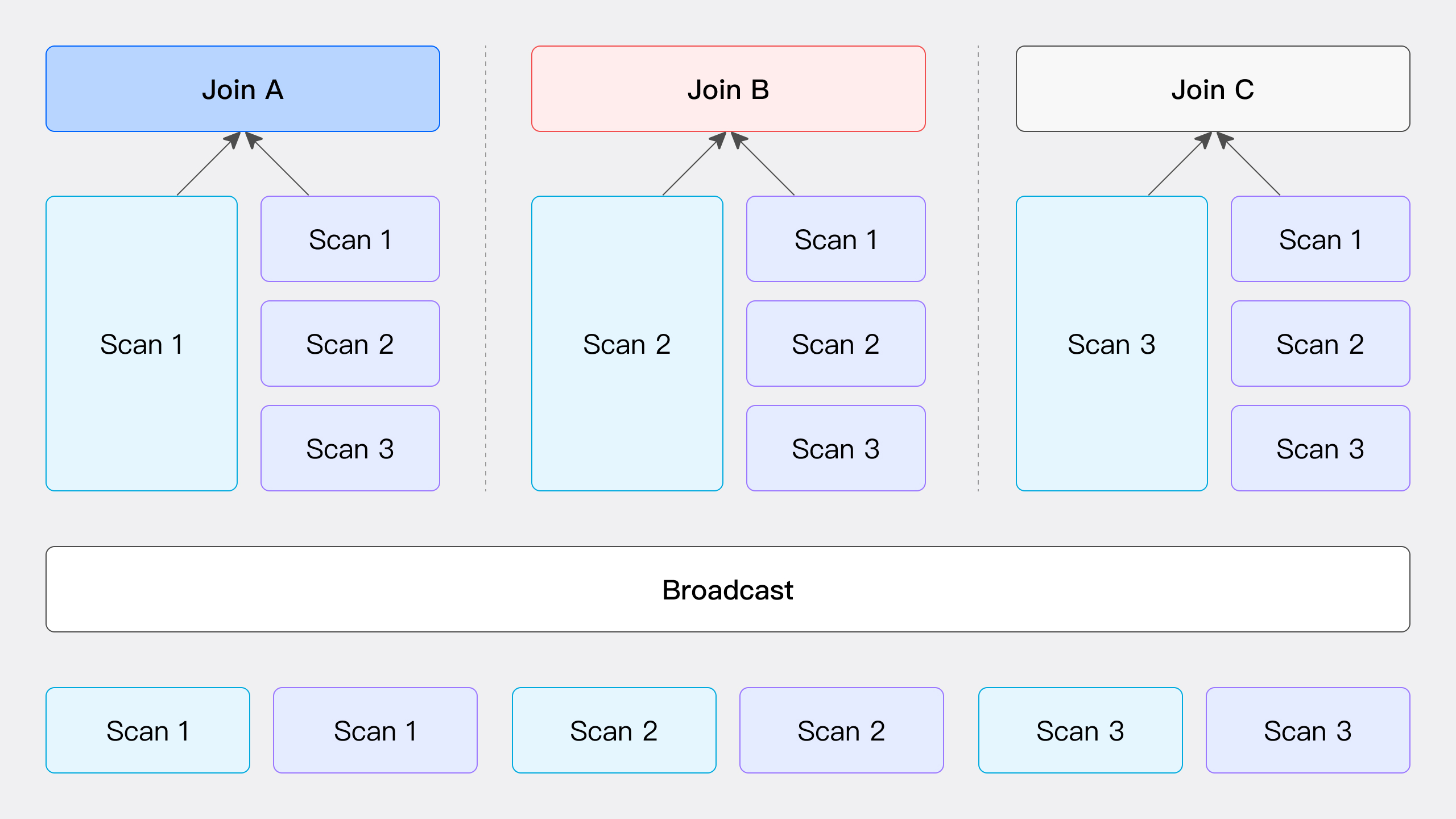
如图所示, Broadcast Join 的过程涉及将右表的所有数据发送到所有参与 Join 计算的节点,包括左表数据的扫描节点,而左表数据则保持不动。这一过程中,每个节点都会接收到右表的完整数据副本(总量为 T(R) 的数据),以确保所有节点都具备执行 Join 操作所需的数据。
该方法适用于多种通用场景,但不适用于 RIGHT OUTER , RIGHT ANTI ,和 RIGHT SEMI 类型的 Hash Join 。其网络开销为 Join 的节点数 N 乘以右表数据量 T(R) 。
4.2 Partition Shuffle Join¶
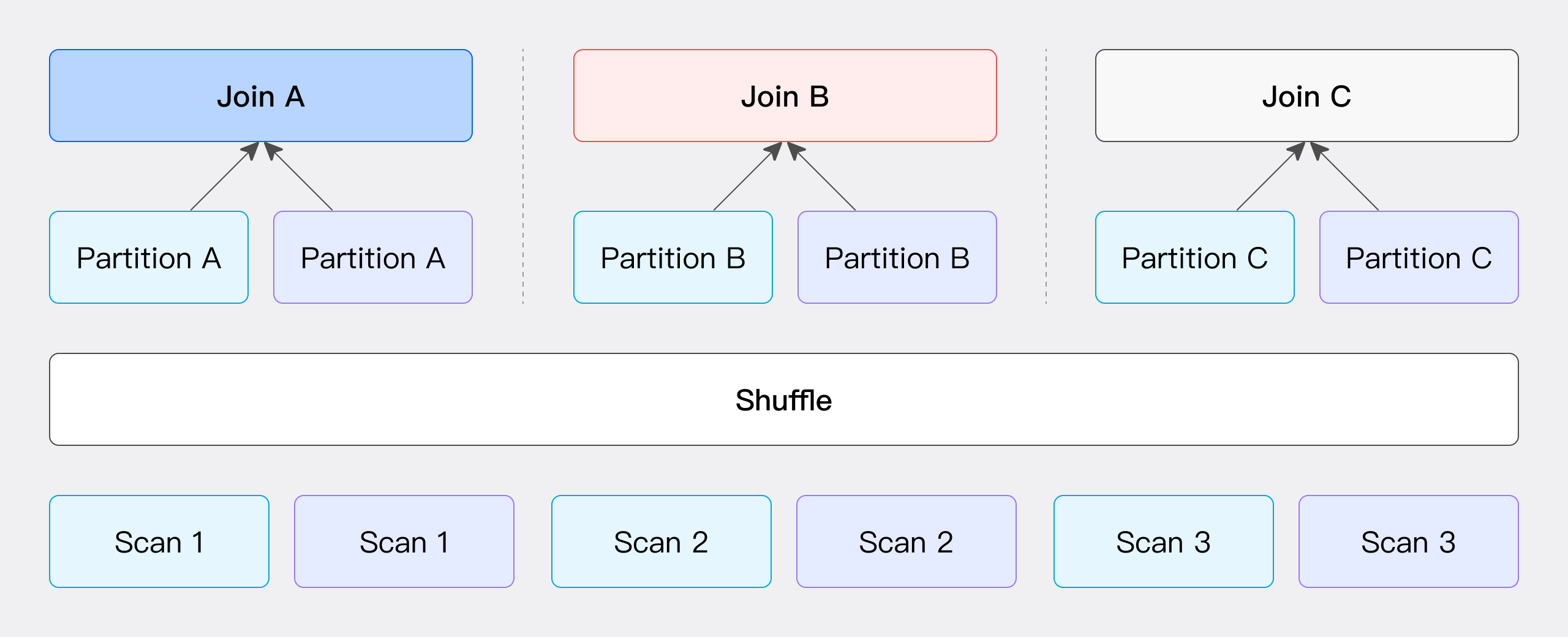
此方式通过 JOIN 条件计算 Hash 值并进行分桶。具体来说,左右表的数据会根据 JOIN 条件计算得到的 Hash 值进行分区,然后这些分区数据被发送到相应的分区节点上(如图所示)。
该方法的网络开销主要包括两个部分:传输左表数据 T(S) 所需的开销和传输右表数据 T(R) 所需的开销。该方法的仅支持 Hash Join 操作,因为它依赖于 JOIN 条件来执行数据的分桶操作。
4.3 Bucket Shuffle Join¶
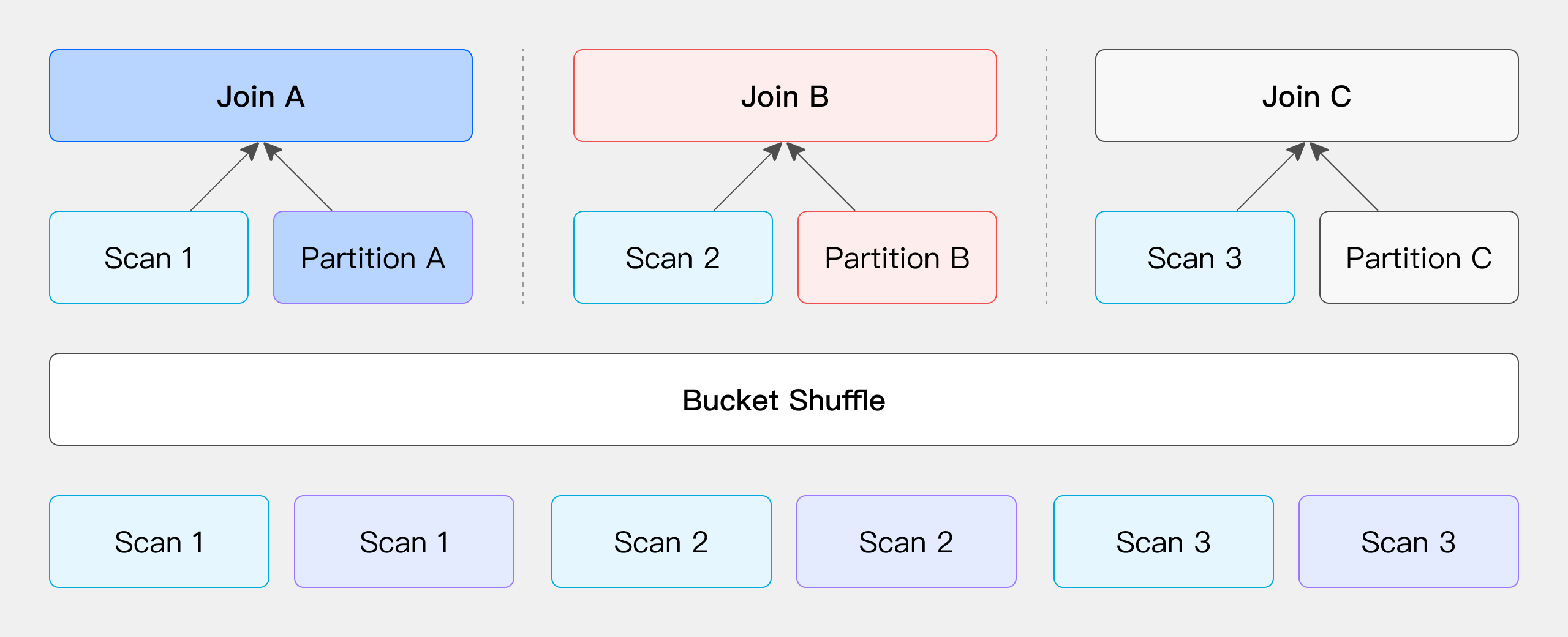
当 JOIN 条件包含左表的分桶列时,保持左表数据不动,将右表数据分发到左表节点进行 JOIN ,减少网络开销。
当参与 Join 操作的某一侧表的数据已经按照 Join 条件列进行了 Hash 分布时,我们可以选择保持这一侧的数据位置不变,而将另一侧的数据依据相同的 Join 条件列,相同的 Hash 分布计算进行数据分发。(这里提到的“表”不仅限于物理存储的表,还可以是 SQL 查询中任意算子的输出结果,并且可以灵活选择保持左表或右表的数据位置不变,而只移动并分发另一侧的表。)
以 Doris 的物理表为例,由于其表数据本身就是通过 Hash 计算进行分桶存储,因此可以直接利用这一特性来优化 Join 操作的数据 Shuffle 过程。假设我们有两张表需要进行 Join ,且 Join 列是左表的分桶列,那么在这种情况下,我们无需移动左表的数据,只需根据左表的分桶信息将右表的数据分发到相应的位置,即可完成 Join 计算(如图所示)。
此过程的网络开销主要来自于右表数据的移动,即 T(R) 。
4.4 Colocate Join¶
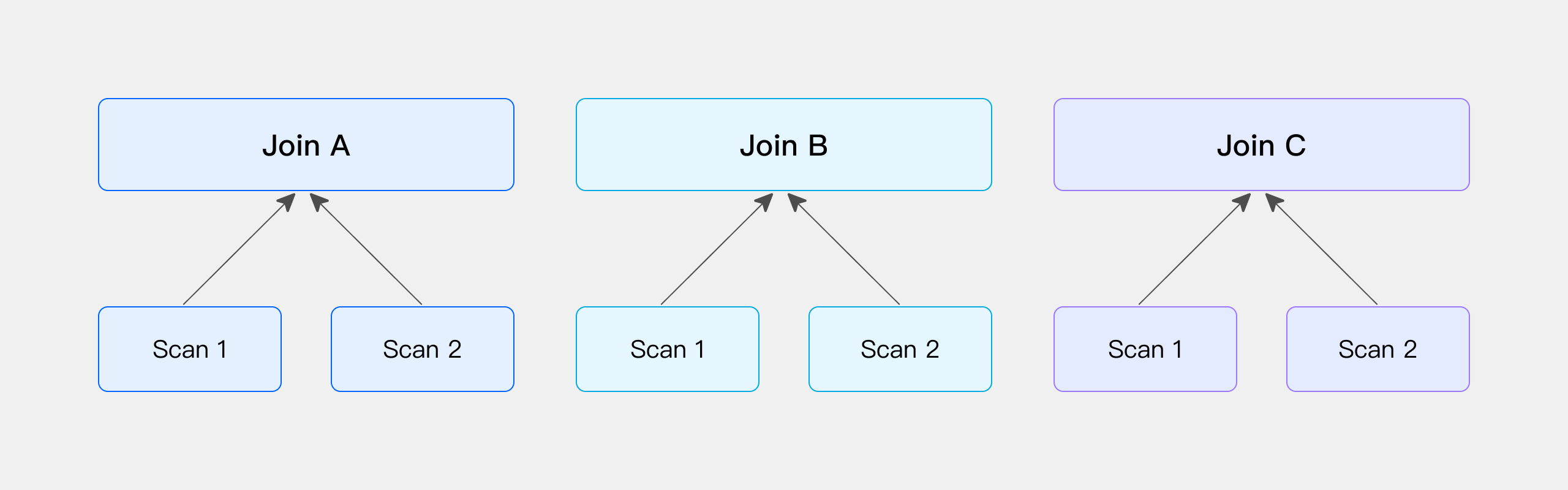
与 Bucket Shuffle Join 相似,如果参与 Join 的两侧的表,刚好是按照 Join 条件列进行计算的 Hash 分布,那么可以跳过 Shuffle 过程,直接在本地进行 Join 计算。以下通过物理表进行简单说明:
当 Doris 在建表时指定为 DISTRIBUTED BY HASH ,那么在数据导入时,系统会根据 Hash 分布键进行数据分发。如果两张表的 Hash 分布键恰好与 Join 条件列一致,那么可以认为这两张表的数据已经按照 Join 的需求进行了预分布,即无需额外的 Shuffle 操作。因此,在实际查询时,可以直接在这两张表上执行 Join 计算。
Warning
对于直接 Scan 数据后执行 Join 的场景,建表时需要满足一定的条件,具体请参考后续关于两张物理表进行 Colocate Join 的限制说明。
5 对比 Bucket Shuffle Join 与 Colocate Join¶
上文我们提到过,对于 Bucket Shuffle Join 和 Colocate Join 只要参与 Join 操作的两侧的表分布满足特定条件,就可以执行相应的 join 操作(这里的表指的是更广义的表,即 SQL 查询中任意算子的输出都可以视为一张“表”)。
接下来,我们将分别通过 t1 和 t2 两张表以及相关的 SQL 示例,来更详细地介绍广义上的 Bucket Shuffle Join 和 Colocate Join 。首先,给出这两张表的建表语句如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
5.1 Bucket Shuffle Join 示例¶
在下面的例子中, t1 和 t2 表都经过了 GROUP BY 算子处理,并输出了新的表(此时 tx 表按照 c1 进行 hash 分布,而 ty 表则按照 c2 进行 Hash 分布)。随后的 JOIN 条件是 tx.c1 = ty.c2 ,这恰好满足了 Bucket Shuffle Join 的条件。
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
从下面的 Explain 执行计划中,我们可以观察到, 7 号 Hash Join 节点的左侧子节点是 6 号聚合节点,而右侧子节点是 4 号 Exchange 节点。这表示左侧子节点聚合后的数据位置保持不变,而右侧子节点的数据则会根据 Bucket Shuffle 的方式被分发到左侧子节点所在的节点上,以便进行后续的 Hash Join 操作。
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 | |
5.2 Colocate Join 示例¶
在下面的例子中, t1 和 t2 表都通过 GROUP BY 算子进行了处理,并输出了新的表(此时 tx 和 ty 均按照 c2 进行了 Hash 分布)。随后的 JOIN 条件是 tx.c2 = ty.c2 ,这恰好满足了 Colocate Join 的条件。
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
从下面的 Explain 执行计划结果中可以看出, 8 号 Hash Join 节点的左侧子节点是 7 号聚合节点,右侧子节点是 3 号聚合节点,并且没有出现 Exchange 节点。这表明左侧和右侧子节点聚合后的数据都保持在其原始位置不动,无需进行数据移动,可以直接在本地进行后续的 Hash Join 操作。
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | |
6 四种 Shuffle 方式对比¶
| Shuffle 方式 | 网络开销 | 物理算子 | 适用场景 |
|---|---|---|---|
| Broadcast | N * T(R) | Hash Join /Nest Loop Join | 通用 |
| Shuffle | T(S) + T(R) | Hash Join | 通用 |
| Bucket Shuffle | T(R) | Hash Join | JOIN 条件含左表分桶列,左表单分区 |
| Colocate | 0 | Hash Join | JOIN 条件含左表分桶列,且两表属同一 Colocate Group |
Tip
N :参与 Join 计算的 Instance 个数
T (关系):关系的 Tuple 数目
上述四种 Shuffle 方式的灵活性依次递减,它们对数据分布的要求也愈发严格。在多数场景下,随着对数据分布要求的提高, Join 计算的性能往往也会逐步提升。值得注意的是,如果表的 Bucket 数量较少, Bucket Shuffle 或 Colocate Join 可能会因为并行度较低而导致性能下降,甚至可能慢于 Shuffle Join 。这是因为 Shuffle 操作能更有效地均衡数据的分布,从而在后续处理中提供更高的并行度。
7 常见问题¶
Bucket Shuffle Join 和 Colocate Join 在应用时对数据分布和 JOIN 条件具有一定限制条件。下面,我们将详细阐述这两种 JOIN 方式各自的具体限制。
7.1 Bucket Shuffle Join 的限制¶
在直接扫描两张物理表以进行 Bucket Shuffle Join 时,需要满足以下条件:
-
等值
Join条件:Bucket Shuffle Join仅适用于Join条件为等值的场景,因为它依赖于Hash计算来确定数据分布。 -
包含分桶列的等值条件:等值
Join条件中须包含两张表的分桶列,当左表的分桶列作为等值Join条件时,更有可能被规划为Bucket Shuffle Join。 -
数据类型一致性:由于不同的数据类型的
hash值计算结果不同,左表的分桶列与右表的等值Join列的数据类型必须一致,否则将无法进行对应的规划。 -
表类型限制:
Bucket Shuffle Join仅适用于Doris原生的OLAP表。对于ODBC、MySQL、ES等外部表,当它们作为左表时,Bucket Shuffle Join无法生效。 -
单分区要求:对于分区表,由于每个分区的数据分布可能不同,
Bucket Shuffle Join仅在左表为单分区时保证有效。因此在执行SQL时,应尽可能使用WHERE条件来启用分区裁剪策略。
7.2 Colocate Join 的限制¶
在直接扫描两张物理表时, Colocate Join 相较于 Bucket Shuffle Join 具有更严格的限制条件,除了满足 Bucket Shuffle Join 的所有条件外,还需满足以下要求:
-
不仅分桶列的类型必须一致,分桶的数量也必须相同,以确保数据分布的一致性。
-
表的副本数必须保持一致。
-
需要显式指定
Colocation Group,只有处于相同Colocation Group的表才能进行Colocate Join。 -
在进行副本修复或副本均衡等操作时,
Colocation Group可能处于Unstable状态,此时Colocate Join将退化为普通的Join操作。