5.5 分析函数 (窗口函数)¶
分析函数,也称为窗口函数,是一种在 SQL 查询中对数据集中的行进行复杂计算的函数。窗口函数的特点在于,它们不会减少查询结果的行数,而是为每一行增加一个新的计算结果。窗口函数适用于多种分析场景,如计算运行总和、排名以及移动平均等。
下面是一个使用窗口函数计算每个商店的前后三天的销售移动平均值的例子:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
查询结果为如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
1 基本概念介绍¶
1.1 处理顺序¶
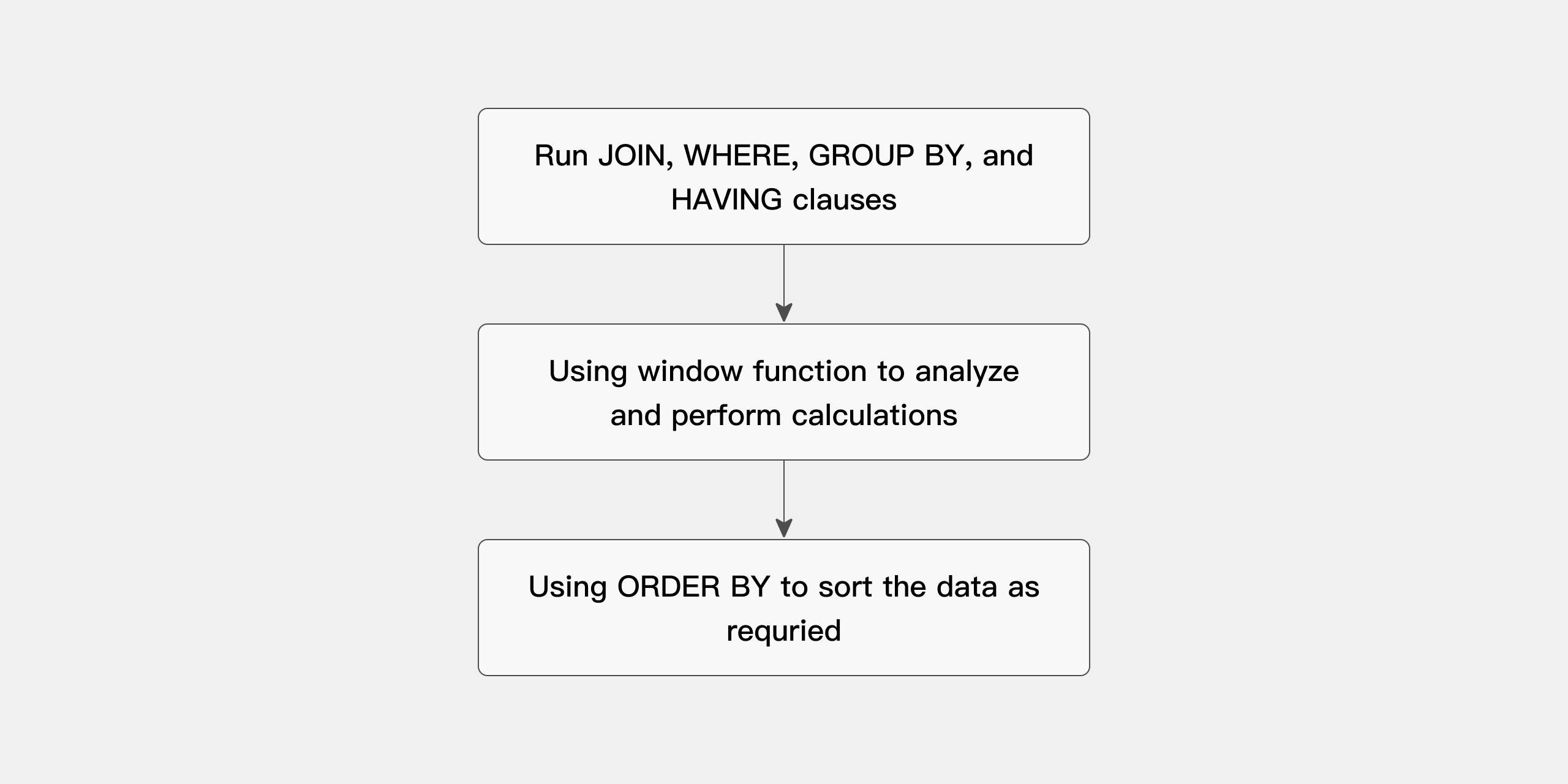
使用分析函数的查询处理可以分为三个阶段。
-
执行所有的连接、
WHERE、GROUP BY和HAVING子句。 -
将结果集提供给分析函数,并进行所有必要的计算。
-
如果查询的末尾包含
ORDER BY子句,则处理该子句以实现精确的输出排序。
查询的处理顺序如图所示:
1.2 结果集分区¶
分区是在使用 PARTITION BY 子句定义的组之后创建的。分析函数允许用户将查询结果集划分为称为分区的行组。
Tip
分析函数中使用的术语“分区”与表分区功能无关。在本章中,术语“分区”仅指与分析函数相关的含义。
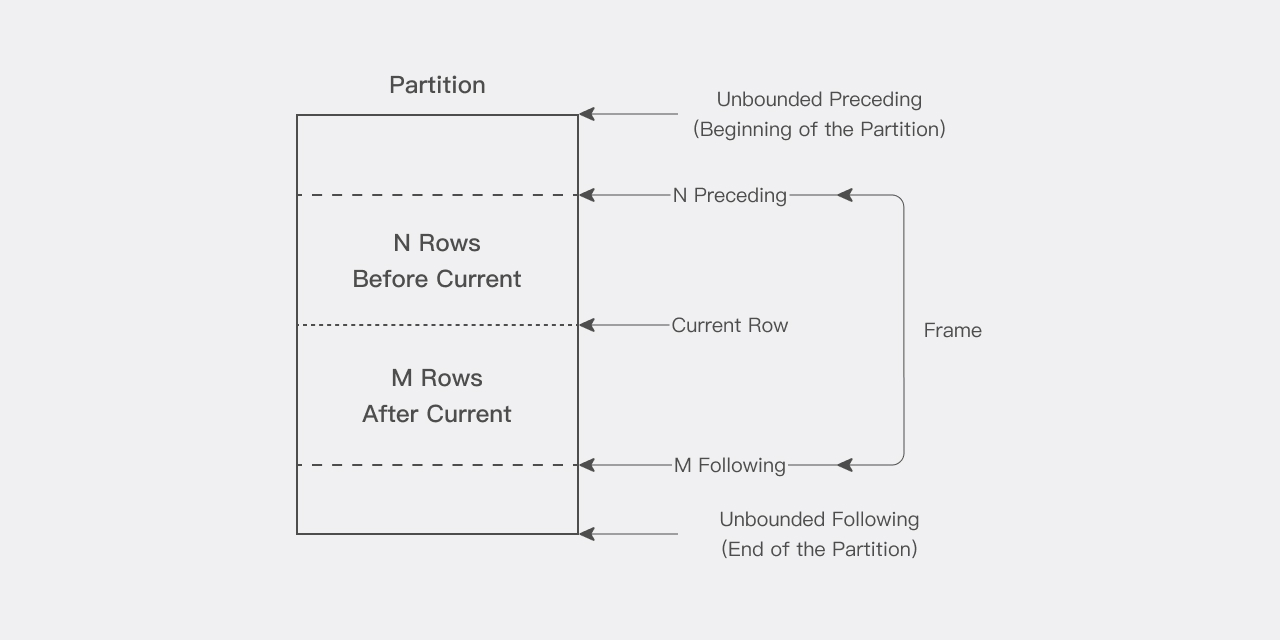
1.3 窗口¶
对于分区中的每一行,你可以定义一个滑动数据窗口。此窗口确定了用于执行当前行计算所涉及的行范围。窗口具有一个起始行和一个结束行,根据其定义,窗口可以在一端或两端进行滑动。例如,为累积和函数定义的窗口,其起始行固定在其分区的第一行,而其结束行则从起点一直滑动到分区的最后一行。相反,为移动平均值定义的窗口,其起点和终点都会进行滑动。
窗口的大小可以设置为与分区中的所有行一样大,也可以设置为在分区内仅包含一行的滑动窗口。需要注意的是,当窗口靠近分区的边界时,由于边界的限制,计算的范围可能会缩减行数,此时函数仅返回可用行的计算结果。
在使用窗口函数时,当前行会被包含在计算之中。因此,在处理 n 个项目时,应指定为 (n-1) 。例如,如果您需要计算五天的平均值,窗口应指定为 "rows between 4 preceding and current row" ,这也可以简写为 "rows 4 preceding" 。
1.4 当前行¶
使用分析函数执行的每个计算都是基于分区内的当前行。当前行作为确定窗口开始和结束的参考点,具体如图所示。
例如,可以使用一个窗口来定义中心移动平均值计算,该窗口包含当前行、当前行之前的 6 行以及当前行之后的 6 行。这样就创建了一个包含 13 行的滑动窗口。
2 排序函数¶
排序函数中,只有当指定的排序列是唯一值列时,查询结果才是确定的;如果排序列包含重复值,则每次的查询结果可能不同。
2.1 NTILE 函数¶
NTILE 是 SQL 中的一种窗口函数,用于将查询结果集分成指定数量的桶(组),并为每一行分配一个桶号。这在数据分析和报告中非常有用,特别是在需要对数据进行分组和排序时。
-
函数语法
SQL 1NTILE(num_buckets) OVER ([PARTITION BY partition_expression] ORDER BY order_expression)-
num_buckets:要将行划分成的桶的数量。 -
PARTITION BY partition_expression(可选):定义如何分区数据。 -
ORDER BY order_expression:定义如何排序数据。
-
-
使用
NTILE函数假设有一个包含学生考试成绩的表
class_student_scores,希望将学生按成绩分成4个组,每组中的学生数量尽可能均匀。首先,创建并插入数据到
class_student_scores表中:SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
CREATE TABLE class_student_scores ( class_id INT, student_id INT, student_name VARCHAR(50), score INT )distributed by hash(student_id) properties('replication_num'=1); INSERT INTO class_student_scores VALUES (1, 1, 'Alice', 85), (1, 2, 'Bob', 92), (1, 3, 'Charlie', 87), (2, 4, 'David', 78), (2, 5, 'Eve', 95), (2, 6, 'Frank', 80), (2, 7, 'Grace', 90), (2, 8, 'Hannah', 84);然后,使用
NTILE函数将学生按成绩分成4个组:SQL 1 2 3 4 5 6 7
SELECT student_id, student_name, score, NTILE(4) OVER (ORDER BY score DESC) AS bucket FROM class_student_scores;结果如下:
SQL 1 2 3 4 5 6 7 8 9 10 11 12 13
+------------+--------------+-------+--------+ | student_id | student_name | score | bucket | +------------+--------------+-------+--------+ | 5 | Eve | 95 | 1 | | 2 | Bob | 92 | 1 | | 7 | Grace | 90 | 2 | | 3 | Charlie | 87 | 2 | | 1 | Alice | 85 | 3 | | 8 | Hannah | 84 | 3 | | 6 | Frank | 80 | 4 | | 4 | David | 78 | 4 | +------------+--------------+-------+--------+ 8 rows in set (0.12 sec)在这个例子中,
NTILE(4)函数根据成绩将学生分成了4个组(桶),每个组的学生数量尽可能均匀。Tip
如果不能均匀地将行分配到桶中,某些桶可能会多一行。
NTILE函数在每个分区内工作,如果使用PARTITION BY子句,则每个分区内的数据将分别进行桶分配。 -
使用
NTILE和PARTITION BY假设按班级对学生进行分组,然后在每个班级内将学生按成绩分成
3个组,可以使用PARTITION BY和NTILE函数:SQL 1 2 3 4 5 6 7 8
SELECT class_id, student_id, student_name, score, NTILE(3) OVER (PARTITION BY class_id ORDER BY score DESC) AS bucket FROM class_student_scores;结果如下:
SQL 1 2 3 4 5 6 7 8 9 10 11 12 13
+----------+------------+--------------+-------+--------+ | class_id | student_id | student_name | score | bucket | +----------+------------+--------------+-------+--------+ | 1 | 2 | Bob | 92 | 1 | | 1 | 3 | Charlie | 87 | 2 | | 1 | 1 | Alice | 85 | 3 | | 2 | 5 | Eve | 95 | 1 | | 2 | 7 | Grace | 90 | 1 | | 2 | 8 | Hannah | 84 | 2 | | 2 | 6 | Frank | 80 | 2 | | 2 | 4 | David | 78 | 3 | +----------+------------+--------------+-------+--------+ 8 rows in set (0.05 sec)在这个例子中,学生按班级进行分区,然后在每个班级内按成绩分成
3个组。每个组的学生数量尽可能均匀。
3 分析函数¶
3.1 使用分析函数 SUM 计算累计值¶
示例如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
查询结果如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
在此示例中,分析函数 SUM 为每一行定义一个窗口,该窗口从分区的开头( UNBOUNDED PRECEDING )开始,默认在当前行结束。在此示例中,需要嵌套使用 SUM ,因为需要对本身就是 SUM 的结果执行 SUM 。嵌套聚合在分析聚合函数中高频使用。
3.2 使用分析函数 AVG 计算移动平均值¶
示例如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
查询结果如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Waring
输出数据中 AVG 列的前两行没有计算三天的移动平均值,因为边界数据前面没有足够的行数(在 SQL 中指定的行数为 3 )。
同时,还可以计算以当前行为中心的窗口聚合函数。例如,此示例计算了 Books 类别的产品在 2000 年各月销售额的中心移动平均值,具体计算的是当前行前一个月、当前行、以及当前行后一个月的销售总额平均值。
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Warning
输出数据中起始行和结束行的中心移动平均值计算仅基于两天,因为边界数据前后没有足够的行数。
4 报告函数¶
报告函数是指每一行的窗口范围都是整个 Partition 。报告函数的主要优点是能够在单个查询块中多次传递数据,从而提高查询性能。例如,“对于每一年,找出其销售额最高的商品类别”之类的查询,使用报告函数则不需要进行 JOIN 操作。示例如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
报告 MAX(SUM(ss_net_paid)) 的内层查询结果如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
完整的查询结果如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 | |
你可以将报告聚合与嵌套查询结合使用,以解决一些复杂的问题,比如查找重要商品子类别中销量最好的产品。以“查找产品销售额占其产品类别总销售额 20% 以上的子类别,并从中选出其中销量最高的五种商品。为例,查询语句如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
5 LAG / LEAD 函数¶
LAG 和 LEAD 函数适用于值之间的比较。两个函数无需进行自连接,皆可以同时访问表中的多个行,从而可以提高查询处理的速度。具体来说, LAG 函数能够提供对当前行之前给定偏移处的行的访问,而 LEAD 函数则提供对当前行之后给定偏移处的行的访问。
以下是一个使用 LAG 函数的 SQL 查询示例,该查询希望选取特定年份( 1999 , 2000 , 2001 , 2002 )中,每个商品类别的总销售额、前一年的总销售额以及两者之间的差异:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
查询结果如下:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
6 分析函数数据的唯一排序¶
-
存在返回结果不一致的问题
当使用窗口函数的
ORDER BY子句未能产生数据的唯一排序时,例如当ORDER BY表达式导致重复值时,行的顺序会变得不确定。这意味着在多次执行查询时,这些行的返回顺序可能会有所不同,进而导致窗口函数返回不一致的结果。通过以下示例可以看出,该查询在多次运行时返回了不同的结果。出现不一致性的情况主要由于
ORDER BY dateid没有为SUM窗口函数提供产生数据的唯一排序。SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
CREATE TABLE test_window_order (item_id int, date_time date, sales double) distributed BY hash(item_id) properties("replication_num" = 1); INSERT INTO test_window_order VALUES (1, '2024-07-01', 100), (2, '2024-07-01', 100), (3, '2024-07-01', 140); SELECT item_id, date_time, sales, sum(sales) OVER (ORDER BY date_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) sum FROM test_window_order;由于排序列
date_time存在重复值,可能呈现以下两种查询结果:SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
+---------+------------+-------+------+ | item_id | date_time | sales | sum | +---------+------------+-------+------+ | 1 | 2024-07-01 | 100 | 100 | | 3 | 2024-07-01 | 140 | 240 | | 2 | 2024-07-01 | 100 | 340 | +---------+------------+-------+------+ 3 rows in set (0.03 sec) +---------+------------+-------+------+ | item_id | date_time | sales | sum | +---------+------------+-------+------+ | 2 | 2024-07-01 | 100 | 100 | | 1 | 2024-07-01 | 100 | 200 | | 3 | 2024-07-01 | 140 | 340 | +---------+------------+-------+------+ 3 rows in set (0.02 sec) -
解决方法
为了解决这个问题,可以在
ORDER BY子句中添加一个唯一值列,如item_id,以确保排序的唯一性。SQL 1 2 3 4 5 6 7 8 9
SELECT item_id, date_time, sales, sum(sales) OVER ( ORDER BY item_id, date_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) sum FROM test_window_order;则查询结果固定为:
SQL 1 2 3 4 5 6 7 8
+---------+------------+-------+------+ | item_id | date_time | sales | sum | +---------+------------+-------+------+ | 1 | 2024-07-01 | 100 | 100 | | 2 | 2024-07-01 | 100 | 200 | | 3 | 2024-07-01 | 140 | 340 | +---------+------------+-------+------+ 3 rows in set (0.03 sec)了解更多有关分析函数信息,可以参考
Oracle官网文档SQL for Analysis and Reporting
7 附录¶
建表和加载数据:
| SQL | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 | |