8.1 概览¶
本文介绍存算分离与存算一体两种架构的区别、优势和适用场景,为用户的选择与使用提供参考。后文将详细说明如何部署并使用 Apache Doris 存算分离模式。如需部署存算一体模式,请参考集群部署。
1 存算一体 VS 存算分离¶
Doris 的整体架构由两类进程组成: Frontend (FE) 和 Backend (BE) 。其中 FE 主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作; BE 主要负责数据存储、查询计划的执行。(更多信息)
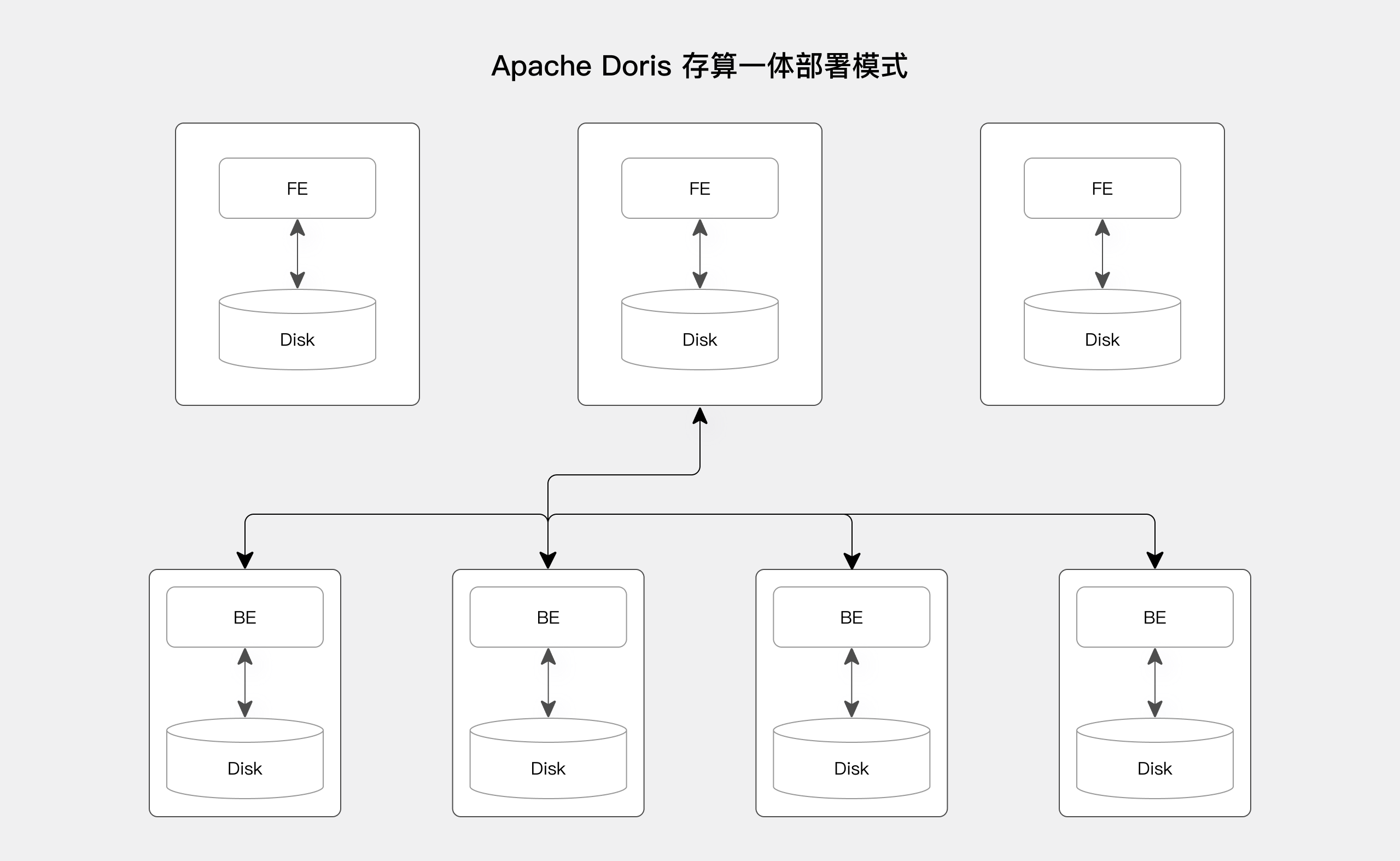
1.1 存算一体¶
在存算一体架构下, BE 节点上存储与计算紧密耦合,数据主要存储在 BE 节点上,多 BE 节点采用 MPP 分布式计算架构。
1.2 存算分离¶
BE 节点不再存储主数据,而是将共享存储层作为统一的数据主存储空间。同时,为了应对底层对象存储系统性能不佳和网络传输带来的性能下降, Doris 引入计算节点本地高速缓存。
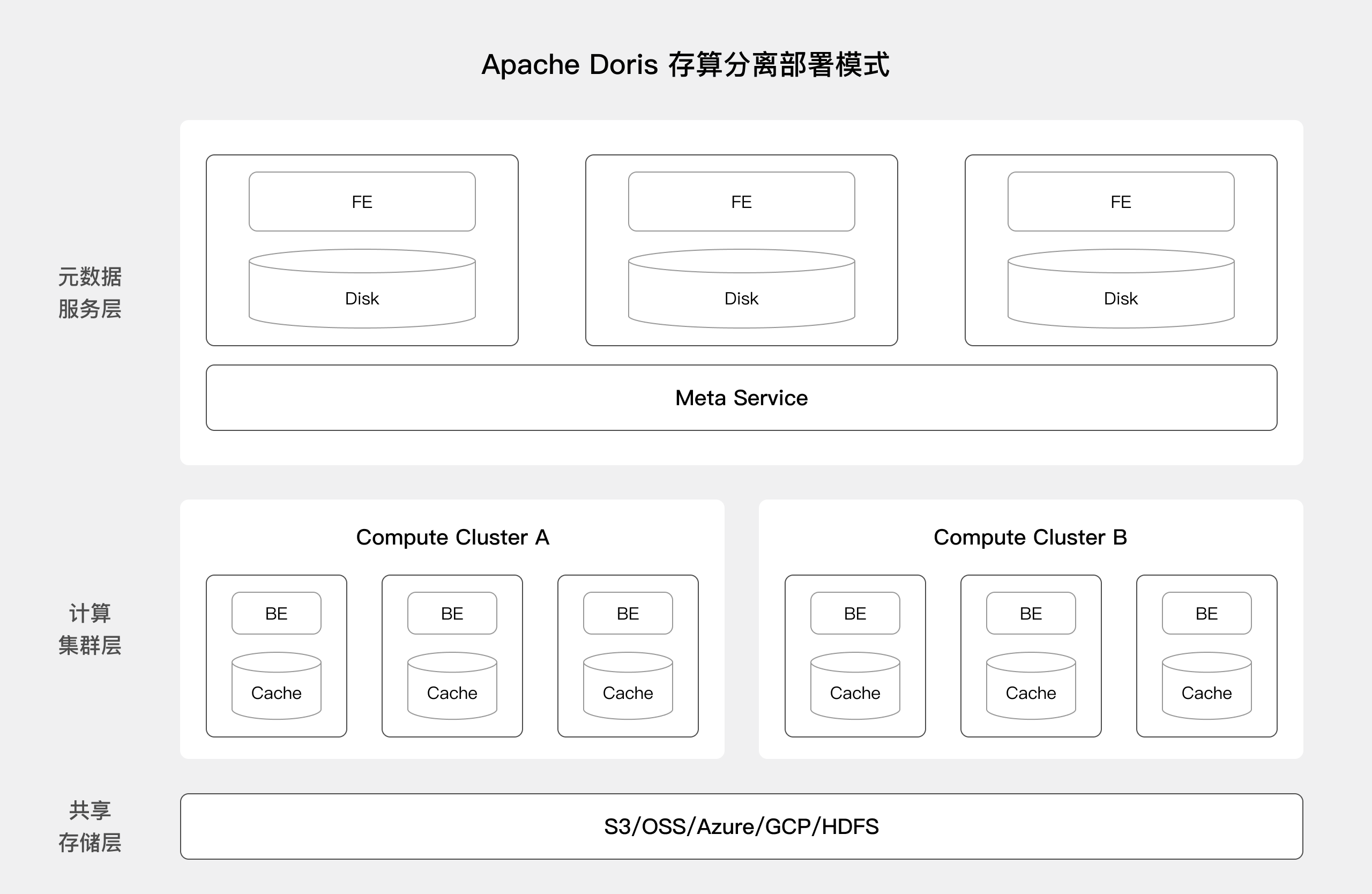
1.2.1 元数据层¶
FE 主要存放库表元数据, Job 以及权限等 MySQL 协议依赖的信息。
Meta Service 是 Doris 存算分离元数据服务,主要负责处理导入事务, Tablet Meta,Rowset Meta 以及集群资源管理。这是一个可以横向扩展的无状态服务。
1.2.2 计算层¶
存算分离模式下的 BE 是无状态的 Doris BE 节点, BE 上会缓存一部分 Tablet 元数据和数据以提高查询性能。
计算集群( Compute Cluster )是无状态的 BE 节点组成的计算资源集合,多个计算集群共享一份数据,计算集群可以随时弹性加减节点。
Tip
存算分离文档中的“计算集群”概念有别于 Doris 【集群部署】以及后文【创建集群】中的“集群”概念。存算分离文档中提及的“计算集群”特指在 Doris 存算分离模式下,由无状态 BE 节点组成的计算资源集合,而非【集群部署】和【创建集群】中所指的由多个 Apache Doris 节点组成的完整分布式系统。
1.2.3 共享存储层¶
共享存储主要存放数据文件,包括 Segment 文件、反向索引的索引文件等。
2 如何选择¶
2.1 存算一体的优点¶
-
部署简易:
Apache Doris不需要依赖类似外部共享文件系统或者对象存储,仅依赖物理服务器部署FE和BE两个进程即可完成集群的搭建,可以从一个节点扩展到数百个节点,同时也增强了系统的稳定性。 -
性能优异:
Apache Doris执行计算时,计算节点可直接访问本地存储数据,充分利用机器的IO、减少不必要的网络开销、获得更极致的查询性能。
2.2 存算一体的适用场景¶
-
简单使用或快速试用
Doris,或在开发和测试环境中使用; -
不具备可靠的共享存储,如
HDFS、Ceph、对象存储等; -
业务线独立维护
Apache Doris,无专职DBA来维护Doris集群; -
不需极致弹性扩缩容,不需
K8s容器化,不需运行在公有云或者私有云上。
2.3 存算分离的优点¶
-
弹性的计算资源:不同时间点使用不同规模的计算资源服务业务请求,按需使用计算资源,节约成本。
-
负载(完全)隔离:不同业务之间可在共享数据的基础上隔离计算资源,兼具稳定性和高效率。
-
低存储成本:可以使用更低成本的对象存储,
HDFS等低成本存储。
2.4 存算分离的适用场景¶
-
已使用公有云服务
-
具备可靠的共享存储系统,比如
HDFS、Ceph、对象存储等 -
需要极致的弹性扩缩容,需要
K8S容器化,需要运行在私有云上 -
有专职团队维护整个公司的数据仓库平台
3 基于存算分离实现多计算集群工作负载隔离¶
如前所述,一个或多个无状态的 BE 节点可以组成计算集群,可以运用计算集群指定语句( use @<compute_group_name> )将特定负载指定到特定的计算集群中,从而实现多导入以及查询负载的物理隔离。
假设当前存在 2 个计算集群: C1 与 C2 。
读读隔离:两个(类)大查询发起之前分别通过 use @c1 , use @c2 实现两个查询使用不同的计算节点运行,使两个查询在访问相同数据集时,不会因 CPU 和内存等资源的竞争而相互干扰。
读写隔离: Doris 的导入会消耗资源,特别是在大数据量和高频导入场景。为了避免查询和导入之间的资源竞争,可以通过 use @c1 , use @c2 指定查询请求在 C1 上执行,导入请求在 C2 上执行。同时, c1 计算集群可以访问 c2 计算集群中新导入的数据。
写写隔离:与读写隔离同理,导入和导入之间同样可以进行隔离。例如,当系统中存在高频小量导入和大批量导入时,批量导入往往耗时长,重试成本高,而高频小量导入单次耗时短,重试成本低,为了避免小量导入对批量导入造成干扰,可以通过 use @c1 , use @c2 ,将小量导入指定到 c1 上执行,批量导入指定到 c2 上执行。