Apache Flink 进阶教程(4):Flink on YarnK8s 原理剖析及实践¶
1 Flink 架构概览¶
1.1 Flink 架构概览–Job¶
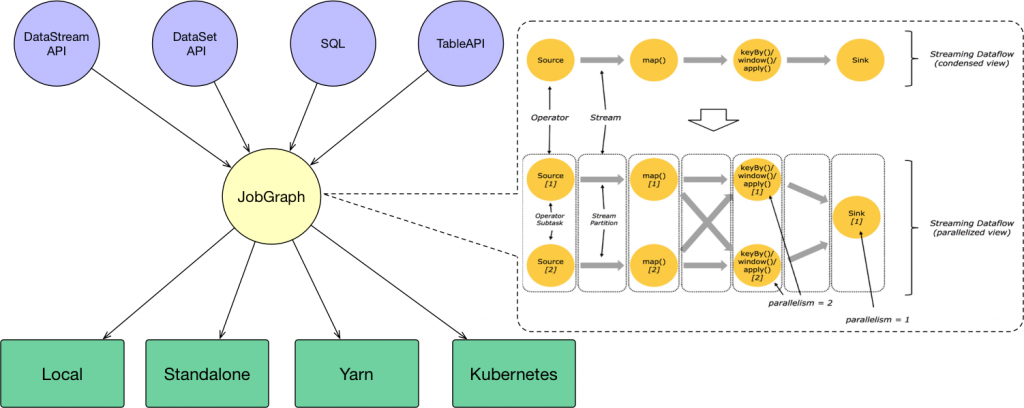
用户通过 DataStream API 、 DataSet API 、 SQL 和 Table API 编写 Flink 任务,它会生成一个 JobGraph 。 JobGraph 是由 source 、 map() 、 keyBy()/window()/apply() 和 Sink 等算子组成的。当 JobGraph 提交给 Flink 集群后,能够以 Local 、 Standalone 、 Yarn 和 Kubernetes 四种模式运行。
1.2 Flink 架构概览–JobManager¶
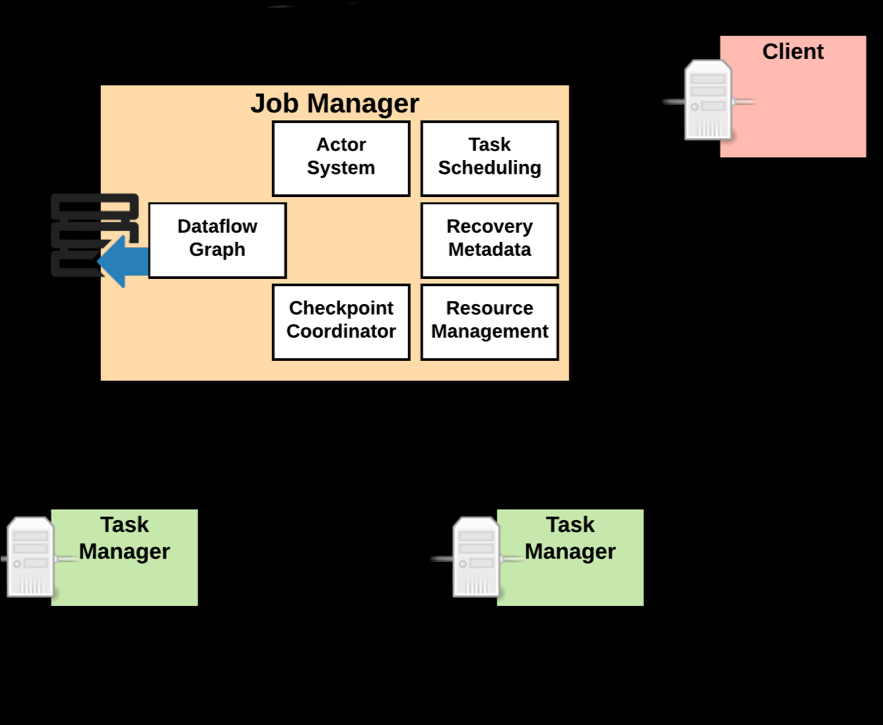
JobManager 的功能主要有:
-
将
JobGraph转换成Execution Graph,最终将Execution Graph拿来运行 -
Scheduler组件负责Task的调度 -
Checkpoint Coordinator组件负责协调整个任务的Checkpoint,包括Checkpoint的开始和完成 -
通过
Actor System与TaskManager进行通信 -
其它的一些功能,例如
Recovery Metadata,用于进行故障恢复时,可以从Metadata里面读取数据。
1.3 Flink 架构概览–TaskManager¶
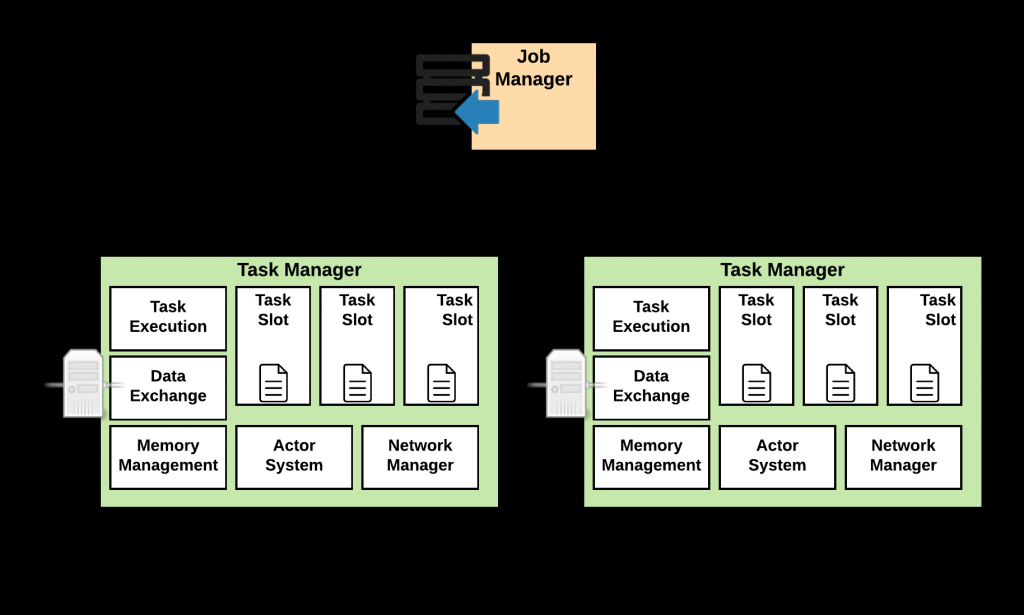
TaskManager 是负责具体任务的执行过程,在 JobManager 申请到资源之后开始启动。 TaskManager 里面的主要组件有:
-
Memory & I/O Manager,即内存I/O的管理 -
Network Manager,用来对网络方面进行管理 -
Actor system,用来负责网络的通信
TaskManager 被分成很多个 TaskSlot ,每个任务都要运行在一个 TaskSlot 里面, TaskSlot 是调度资源里的最小单位。
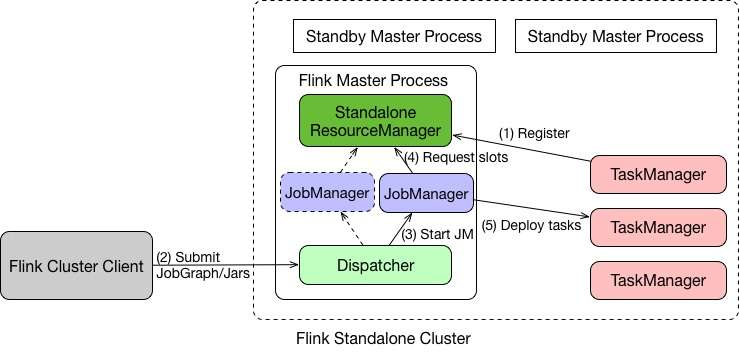
在介绍 Yarn 之前先简单的介绍一下 Flink Standalone 模式,这样有助于更好地了解 Yarn 和 Kubernetes 架构。
-
在
Standalone模式下,Master和TaskManager可以运行在同一台机器上,也可以运行在不同的机器上。 -
在
Master进程中,Standalone ResourceManager的作用是对资源进行管理。当用户通过Flink Cluster Client将JobGraph提交给Master时,JobGraph先经过Dispatcher。 -
当
Dispatcher收到客户端的请求之后,生成一个JobManager。接着JobManager进程向Standalone ResourceManager申请资源,最终再启动TaskManager。 -
TaskManager启动之后,会有一个注册的过程,注册之后JobManager再将具体的Task任务分发给这个TaskManager去执行。
以上就是一个 Standalone 任务的运行过程。
1.4 Flink 运行时相关组件¶
接下来总结一下 Flink 的基本架构和它在运行时的一些组件,具体如下:
-
Client:用户通过SQL或者API的方式进行任务的提交,提交后会生成一个JobGraph。 -
JobManager:JobManager接受到用户的请求之后,会对任务进行调度,并且申请资源启动TaskManager。 -
TaskManager:它负责一个具体Task的执行。TaskManager向JobManager进行注册,当TaskManager接收到JobManager分配的任务之后,开始执行具体的任务。
2 Flink on Yarn 原理及实践¶
2.1 Yarn 架构原理–总览¶
Yarn 模式在国内使用比较广泛,基本上大多数公司在生产环境中都使用过 Yarn 模式。首先介绍一下 Yarn 的架构原理,因为只有足够了解 Yarn 的架构原理,才能更好的知道 Flink 是如何在 Yarn 上运行的。
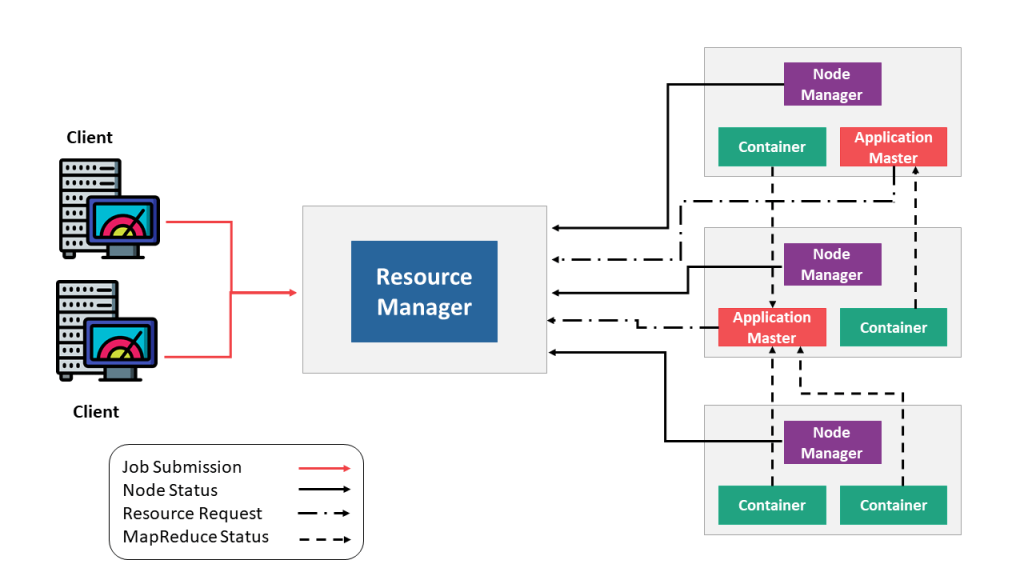
Yarn 的架构原理如上图所示,最重要的角色是 ResourceManager ,主要用来负责整个资源的管理, Client 端是负责向 ResourceManager 提交任务。
用户在 Client 端提交任务后会先给到 Resource Manager 。 Resource Manager 会启动 Container ,接着进一步启动 Application Master ,即对 Master 节点的启动。当 Master 节点启动之后,会向 Resource Manager 再重新申请资源,当 Resource Manager 将资源分配给 Application Master 之后, Application Master 再将具体的 Task 调度起来去执行。
2.2 Yarn 架构原理–组件¶
Yarn 集群中的组件包括:
-
ResourceManager (RM):ResourceManager (RM)负责处理客户端请求、启动或监控ApplicationMaster、监控NodeManager、资源的分配与调度,包含Scheduler和Applications Manager。 -
ApplicationMaster (AM):ApplicationMaster (AM)运行在Slave上,负责数据切分、申请资源和分配、任务监控和容错。 -
NodeManager (NM):NodeManager (NM)运行在Slave上,用于单节点资源管理、AM/RM通信以及汇报状态。 -
Container:Container负责对资源进行抽象,包括内存、CPU、磁盘,网络等资源。
2.3 Yarn 架构原理–交互¶
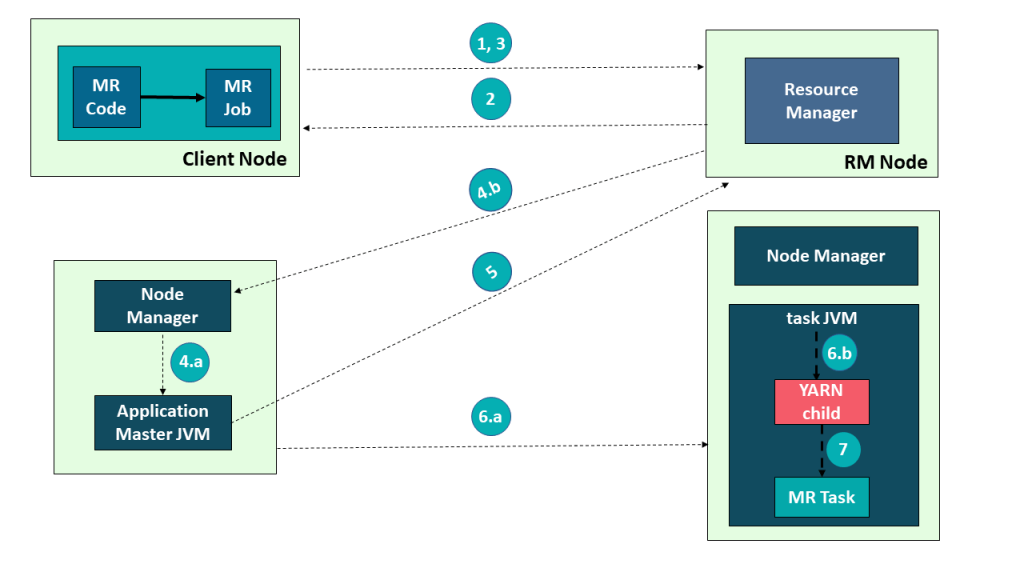
以在 Yarn 上运行 MapReduce 任务为例来讲解下 Yarn 架构的交互原理:
-
首先,用户编写
MapReduce代码后,通过Client端进行任务提交 -
ResourceManager在接收到客户端的请求后,会分配一个Container用来启动ApplicationMaster,并通知NodeManager在这个Container下启动ApplicationMaster。 -
ApplicationMaster启动后,向ResourceManager发起注册请求。接着ApplicationMaster向ResourceManager申请资源。根据获取到的资源,和相关的NodeManager通信,要求其启动程序。 -
一个或者多个
NodeManager启动Map/Reduce Task。 -
NodeManager不断汇报Map/Reduce Task状态和进展给ApplicationMaster。 -
当所有
Map/Reduce Task都完成时,ApplicationMaster向ResourceManager汇报任务完成,并注销自己。
2.4 Flink on Yarn–Per Job¶
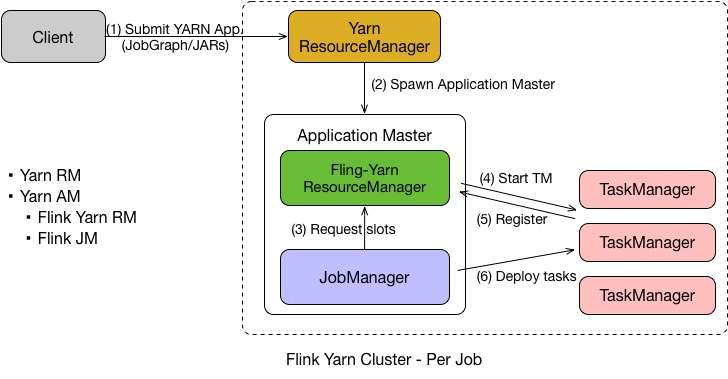
Flink on Yarn 中的 Per Job 模式是指每次提交一个任务,然后任务运行完成之后资源就会被释放。在了解了 Yarn 的原理之后, Per Job 的流程也就比较容易理解了,具体如下:
-
首先
Client提交Yarn App,比如JobGraph或者JARs。 -
接下来
Yarn的ResourceManager会申请第一个Container。这个Container通过Application Master启动进程,Application Master里面运行的是Flink程序,即Flink-Yarn ResourceManager和JobManager。 -
最后
Flink-Yarn ResourceManager向Yarn ResourceManager申请资源。当分配到资源后,启动TaskManager。TaskManager启动后向Flink-Yarn ResourceManager进行注册,注册成功后JobManager就会分配具体的任务给TaskManager开始执行。
2.5 Flink on Yarn–Session¶
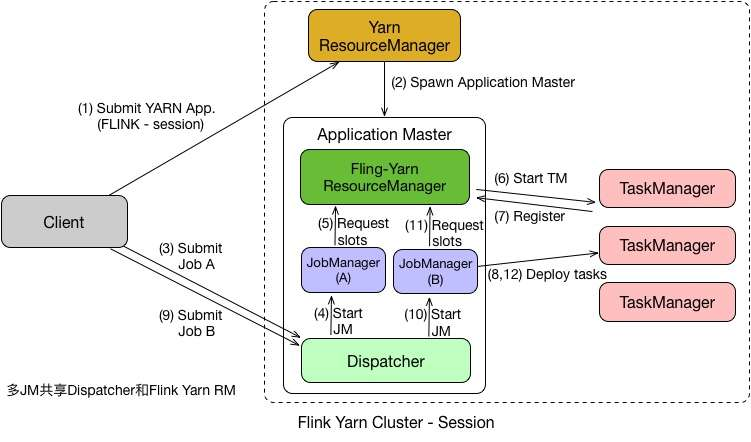
在 Per Job 模式中,执行完任务后整个资源就会释放,包括 JobManager 、 TaskManager 都全部退出。而 Session 模式则不一样,它的 Dispatcher 和 ResourceManager 是可以复用的。 Session 模式下,当 Dispatcher 在收到请求之后,会启动 JobManager(A) ,让 JobManager(A) 来完成启动 TaskManager ,接着会启动 JobManager(B) 和对应的 TaskManager 的运行。当 A 、 B 任务运行完成后,资源并不会释放。 Session 模式也称为多线程模式,其特点是资源会一直存在不会释放,多个 JobManager 共享一个 Dispatcher ,而且还共享 Flink-YARN ResourceManager 。
Session 模式和 Per Job 模式的应用场景不一样。 Per Job 模式比较适合那种对启动时间不敏感,运行时间较长的任务。 Seesion 模式适合短时间运行的任务,一般是批处理任务。若用 Per Job 模式去运行短时间的任务,那就需要频繁的申请资源,运行结束后,还需要资源释放,下次还需再重新申请资源才能运行。显然,这种任务会频繁启停的情况不适用于 Per Job 模式,更适合用 Session 模式。
2.6 Yarn 模式特点¶
Yarn 模式的优点有:
-
资源的统一管理和调度。
Yarn集群中所有节点的资源(内存、CPU、磁盘、网络等)被抽象为Container。计算框架需要资源进行运算任务时需要向Resource Manager申请Container,YARN按照特定的策略对资源进行调度和进行Container的分配。Yarn模式能通过多种任务调度策略来利用提高集群资源利用率。例如FIFO Scheduler、Capacity Scheduler、Fair Scheduler,并能设置任务优先级。 -
资源隔离:
Yarn使用了轻量级资源隔离机制Cgroups进行资源隔离以避免相互干扰,一旦Container使用的资源量超过事先定义的上限值,就将其杀死。 -
自动
failover处理。例如Yarn NodeManager监控、Yarn ApplicationManager异常恢复。
Yarn 模式虽然有不少优点,但是也有诸多缺点,例如运维部署成本较高,灵活性不够。
2.7 Flink on Yarn 实践¶
关于 Flink on Yarn 的实践在本站上面有很多课程,例如:《 Flink 安装部署、环境配置及运行应用程序》和《客户端操作》都是基于 Yarn 进行讲解的,这里就不再赘述。
3 Flink on Kubernetes 原理剖析¶
Kubernetes 是 Google 开源的容器集群管理系统,其提供应用部署、维护、扩展机制等功能,利用 Kubernetes 能方便地管理跨机器运行容器化的应用。 Kubernetes 和 Yarn 相比,相当于下一代的资源管理系统,但是它的能力远远不止这些。
3.1 Kubernetes–基本概念¶
Kubernetes(k8s) 中的 Master 节点,负责管理整个集群,含有一个集群的资源数据访问入口,还包含一个 Etcd 高可用键值存储服务。 Master 中运行着 API Server , Controller Manager 及 Scheduler 服务。
Node 为集群的一个操作单元,是 Pod 运行的宿主机。 Node 节点里包含一个 agent 进程,能够维护和管理该 Node 上的所有容器的创建、启停等。 Node 还含有一个服务端 kube-proxy ,用于服务发现、反向代理和负载均衡。 Node 底层含有 docker engine , docker 引擎主要负责本机容器的创建和管理工作。
Pod 运行于 Node 节点上,是若干相关容器的组合。在 K8s 里面 Pod 是创建、调度和管理的最小单位。
3.2 Kubernetes–架构图¶
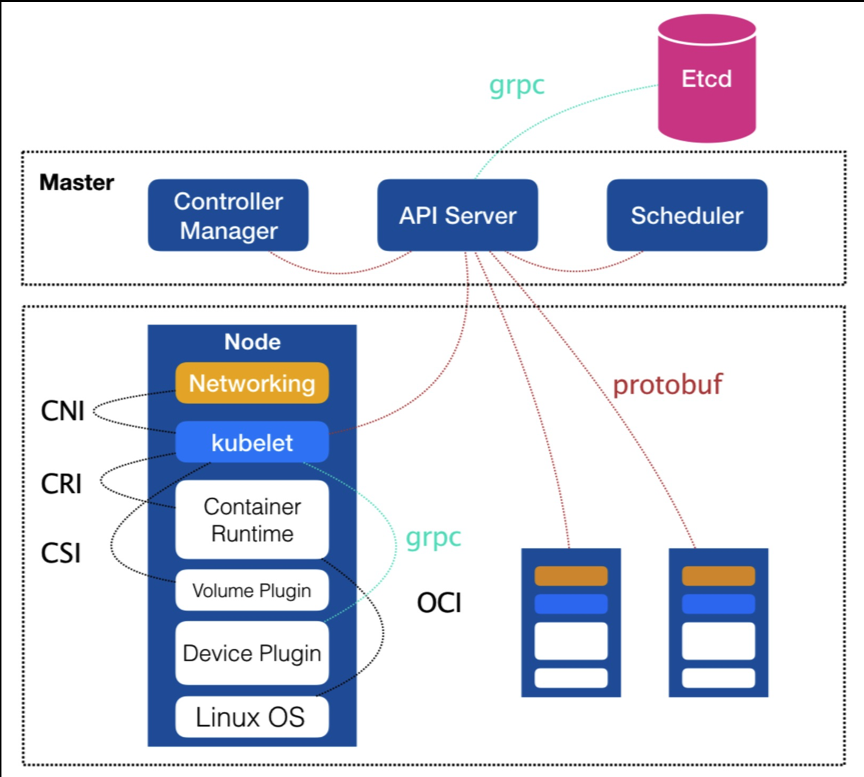
Kubernetes 的架构如图所示,从这个图里面能看出 Kubernetes 的整个运行过程。
-
API Server相当于用户的一个请求入口,用户可以提交命令给Etcd,这时会将这些请求存储到Etcd里面去。 -
Etcd是一个键值存储,负责将任务分配给具体的机器,在每个节点上的Kubelet会找到对应的container在本机上运行。 -
用户可以提交一个
Replication Controller资源描述,Replication Controller会监视集群中的容器并保持数量;用户也可以提交service描述文件,并由kube proxy负责具体工作的流量转发。
3.3 Kubernetes–核心概念¶
Kubernetes 中比较重要的概念有:
-
Replication Controller (RC)用来管理Pod的副本。RC确保任何时候Kubernetes集群中有指定数量的pod副本(replicas)在运行,如果少于指定数量的pod副本,RC会启动新的Container,反之会杀死多余的以保证数量不变。 -
Service提供了一个统一的服务访问入口以及服务代理和发现机制 -
Persistent Volume(PV)和Persistent Volume Claim(PVC)用于数据的持久化存储。 -
ConfigMap是指存储用户程序的配置文件,其后端存储是基于Etcd。
3.4 Flink on Kubernetes–架构¶
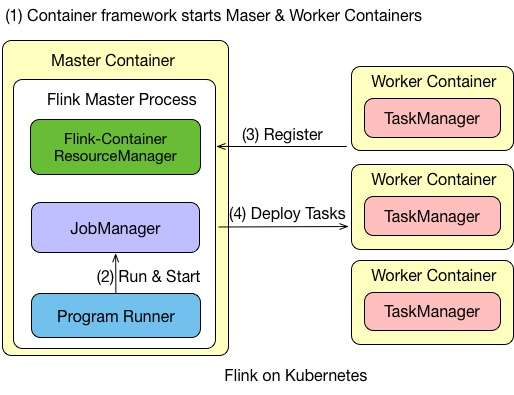
Flink on Kubernetes 的架构如图所示, Flink 任务在 Kubernetes 上运行的步骤有:
-
首先往
Kubernetes集群提交了资源描述文件后,会启动Master和Worker的container。 -
Master Container中会启动Flink Master Process,包含Flink-Container ResourceManager、JobManager和Program Runner。 -
Worker Container会启动TaskManager,并向负责资源管理的ResourceManager进行注册,注册完成之后,由JobManager将具体的任务分给Container,再由Container去执行。 -
需要说明的是,在
Flink里的Master和Worker都是一个镜像,只是脚本的命令不一样,通过参数来选择启动master还是启动Worker。
3.5 Flink on Kubernetes–JobManager¶
JobManager 的执行过程分为两步:
-
首先,
JobManager通过Deployment进行描述,保证1个副本的Container运行JobManager,可以定义一个标签,例如flink-jobmanager。 -
其次,还需要定义一个
JobManager Service,通过service name和port暴露JobManager服务,通过标签选择对应的pods。
3.6 Flink on Kubernetes–TaskManager¶
TaskManager 也是通过 Deployment 来进行描述,保证 n 个副本的 Container 运行 TaskManager ,同时也需要定义一个标签,例如 flink-taskmanager 。
对于 JobManager 和 TaskManager 运行过程中需要的一些配置文件,如: flink-conf.yaml 、 hdfs-site.xml 、 core-site.xml ,可以通过将它们定义为 ConfigMap 来实现配置的传递和读取。
3.7 Flink on Kubernetes–交互¶
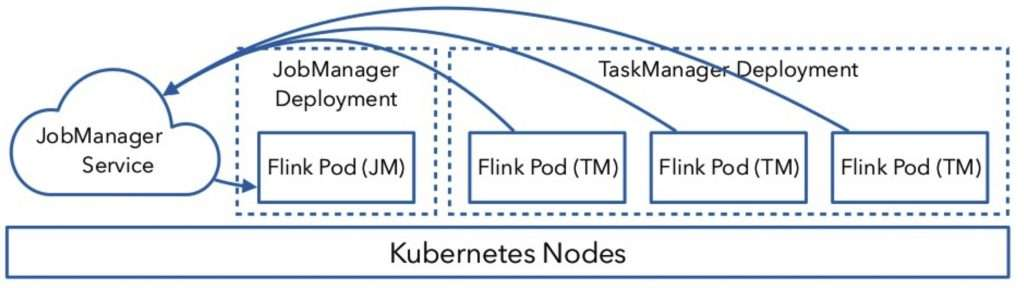
整个交互的流程比较简单,用户往 Kubernetes 集群提交定义好的资源描述文件即可,例如 deployment 、 configmap 、 service 等描述。后续的事情就交给 Kubernetes 集群自动完成。 Kubernetes 集群会按照定义好的描述来启动 pod ,运行用户程序。各个组件的具体工作如下:
-
Service:通过标签(label selector)找到job manager的pod暴露服务。 -
Deployment:保证n个副本的container运行JM/TM,应用升级策略。 -
ConfigMap:在每个pod上通过挂载/etc/flink目录,包含flink-conf.yaml内容。
3.8 Flink on Kubernetes–实践¶
接下来就讲一下 Flink on Kubernetes 的实践篇,即 K8s 上是怎么运行任务的。
3.8.1 Session Cluster¶
| Bash | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
首先启动 Session Cluster ,执行上述三条启动命令就可以将 Flink 的 JobManager-service 、 jobmanager-deployment 、 taskmanager-deployment 启动起来。启动完成之后用户可以通过接口进行访问,然后通过端口进行提交任务。若想销毁集群,直接用 kubectl delete 即可,整个资源就可以销毁。

Flink 官方提供的例子如图所示图中左侧为 jobmanager-deployment.yaml 配置,右侧为 taskmanager-deployment.yaml 配置。
在 jobmanager-deployment.yaml 配置中,代码的第一行为 apiVersion , apiVersion 是 API 的一个版本号,版本号用的是 extensions/vlbetal 版本。资源类型为 Deployment ,元数据 metadata 的名为 flink-jobmanager , spec 中含有副本数为 1 的 replicas , labels 标签用于 pod 的选取。 containers 的镜像名为 jobmanager , containers 包含从公共 docker 仓库下载的 image ,当然也可以使用公司内部的私有仓库。 args 启动参数用于决定启动的是 jobmanager 还是 taskmanager ; ports 是服务端口,常见的服务端口为 8081 端口; env 是定义的环境变量,会传递给具体的启动脚本。
右图为 taskmanager-deployment.yaml 配置, taskmanager-deployment.yaml 配置与 jobmanager-deployment.yaml 相似,但 taskmanager-deployment.yaml 的副本数是 2 个。
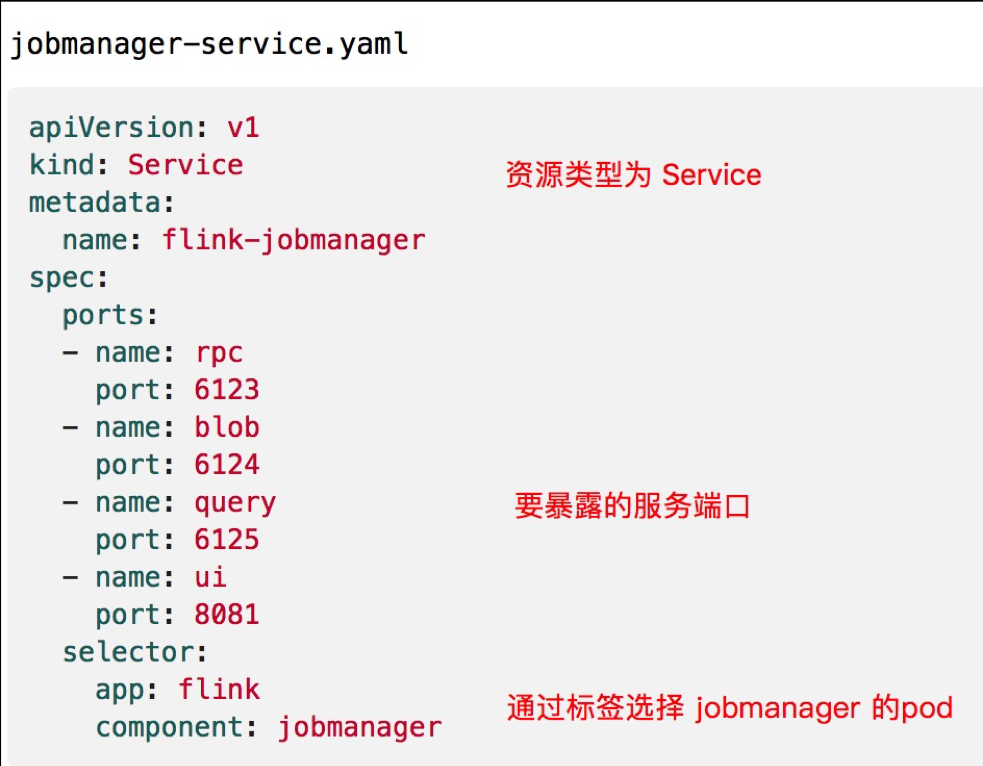
接下来是 jobmanager-service.yaml 的配置, jobmanager-service.yaml 的资源类型为 Service ,在 Service 中的配置相对少一些, spec 中配置需要暴露的服务端口的 port ,在 selector 中,通过标签选取 jobmanager 的 pod 。
3.8.2 Job Cluster¶
除了 Session 模式,还有一种 Per Job 模式。在 Per Job 模式下,需要将用户代码都打到镜像里面,这样如果业务逻辑的变动涉及到 Jar 包的修改,都需要重新生成镜像,整个过程比较繁琐,因此在生产环境中使用的比较少。
以使用公用 docker 仓库为例, Job Cluster 的运行步骤如下:
build镜像:在flink/flink-container/docker目录下执行build.sh脚本,指定从哪个版本开始去构建镜像,成功后会输出Successfully tagged topspeed:latest的提示。
| Bash | |
|---|---|
1 | |
- 上传镜像:在
hub.docker.com上需要注册账号和创建仓库进行上传镜像。
| Bash | |
|---|---|
1 2 | |
- 启动任务:在镜像上传之后,可以启动任务。
| Bash | |
|---|---|
1 2 3 | |
4 Flink on Yarn/Kubernetes问题解答¶
4.1 Flink 在 K8s 上可以通过 Operator 方式提交任务吗?¶
目前 Flink 官方还没有提供 Operator 的方式, Lyft 公司开源了自己的 Operator 实现:https://github.com/lyft/flinkk8soperator。
4.2 在 K8s 集群上如果不使用 Zookeeper 有没有其他高可用(HA)的方案?¶
Etcd 是一个类似于 Zookeeper 的高可用键值服务,目前 Flink 社区正在考虑基于 Etcd 实现高可用的方案(https://issues.apache.org/jira/browse/FLINK-11105)以及直接依赖 K8s API 的方案(https://issues.apache.org/jira/browse/FLINK-12884)
4.3 Flink on K8s 在任务启动时需要指定 TaskManager 的个数,有和 Yarn 一样的动态资源申请方式吗?¶
Flink on K8s 目前的实现在任务启动前就需要确定好 TaskManager 的个数,这样容易造成 TM 指定太少,任务无法启动,或者指定的太多,造成资源浪费。社区正在考虑实现和 Yarn 一样的任务启动时动态资源申请的方式。这是一种和 K8s 结合的更为 Nativey 的方式,称为 Active 模式。 Active 意味着 ResourceManager 可以直接向 K8s 集群申请资源。具体设计方案和进展请关注:https://issues.apache.org/jira/browse/FLINK-9953