Apache Flink 进阶教程(6):Flink 作业执行深度解析¶
1 Flink 四层转化流程¶
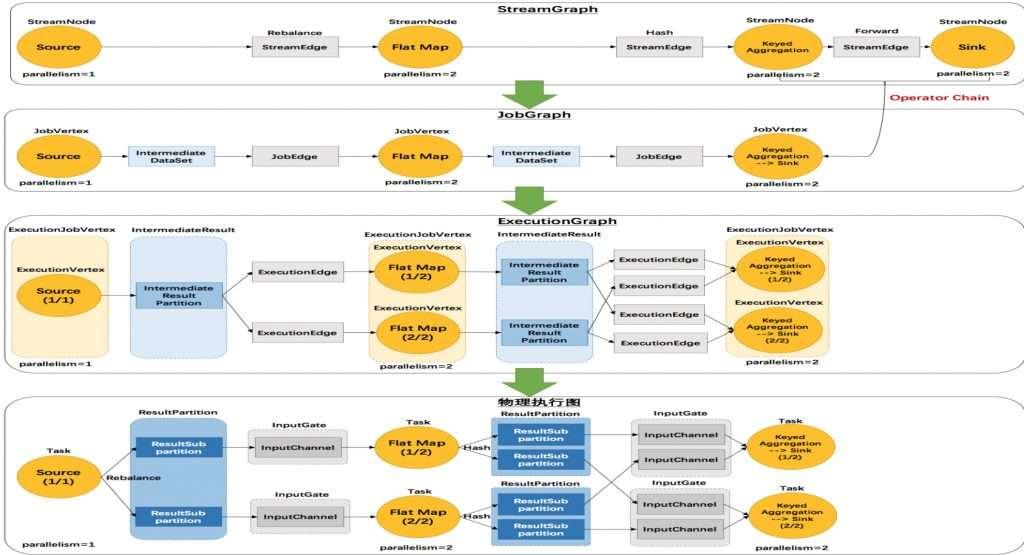
Flink 有四层转换流程,第一层为 Program 到 StreamGraph ;第二层为 StreamGraph 到 JobGraph ;第三层为 JobGraph 到 ExecutionGraph ;第四层为 ExecutionGraph 到物理执行计划。通过对 Program 的执行,能够生成一个 DAG 执行图,即逻辑执行图。如下:
第一部分将先讲解四层转化的流程,然后将以详细案例讲解四层的具体转化。
-
第一层
StreamGraph从Source节点开始,每一次transform生成一个StreamNode,两个StreamNode通过StreamEdge连接在一起,形成StreamNode和StreamEdge构成的DAG。 -
第二层
JobGraph,依旧从Source节点开始,然后去遍历寻找能够嵌到一起的operator,如果能够嵌到一起则嵌到一起,不能嵌到一起的单独生成jobVertex,通过JobEdge链接上下游JobVertex,最终形成JobVertex层面的DAG。 -
JobVertex DAG提交到任务以后,从Source节点开始排序,根据JobVertex生成ExecutionJobVertex,根据jobVertex的IntermediateDataSet构建IntermediateResult,然后IntermediateResult构建上下游的依赖关系,形成ExecutionJobVertex层面的DAG即ExecutionGraph。 -
最后通过
ExecutionGraph层到物理执行层。
1.1 Program 到 StreamGraph 的转化¶
Program 转换成 StreamGraph 具体分为三步:
-
从
StreamExecutionEnvironment.execute开始执行程序,将transform添加到StreamExecutionEnvironment的transformations。 -
调用
StreamGraphGenerator的generateInternal方法,遍历transformations构建StreamNode及StreamEage。 -
通过
StreamEdge连接StreamNode。
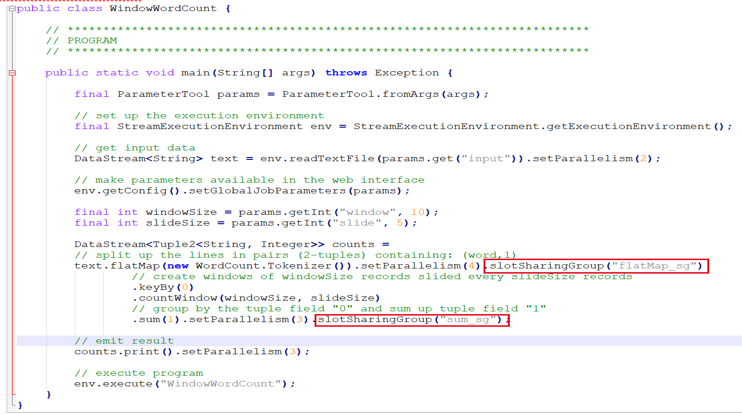
通过 WindowWordCount 来看代码到 StreamGraph 的转化,在 flatMap transform 设置 slot 共享组为 flatMap_sg ,并发设置为 4 ,在聚合的操作中设置 slot 共享组为 sum_sg , sum() 和 counts() 并发设置为 3 ,这样设置主要是为了演示后面如何嵌到一起的,跟上下游节点的并发以及上游的共享组有关。
WindowWordCount 代码中可以看到,在 readTextFile() 中会生成一个 transform ,且 transform 的 ID 是 1 ;然后到 flatMap() 会生成一个 transform , transform 的 ID 是 2 ;接着到 keyBy() 生成一个 transform 的 ID 是 3 ;再到 sum() 生成一个 transform 的 ID 是 4 ;最后到 counts() 生成 transform 的 ID 是 5 。
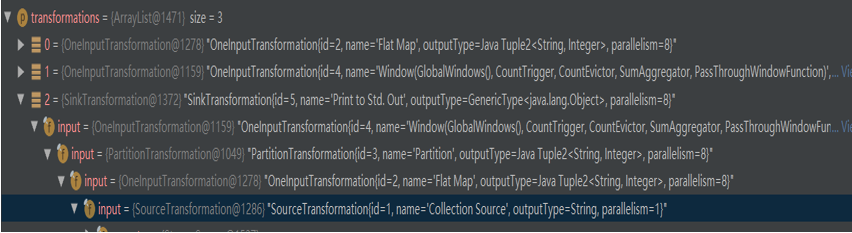
transform 的结构如图所示,第一个是 flatMap 的 transform ,第二个是 window 的 transform ,第三个是 SinkTransform 的 transform 。除此之外,还能在 transform 的结构中看到每个 transform 的 input 是什么。
接下来介绍一下 StreamNode 和 StreamEdge 。
-
StreamNode是用来描述operator的逻辑节点,其关键成员变量有slotSharingGroup、jobVertexClass、inEdges、outEdges以及transformationUID; -
StreamEdge是用来描述两个operator逻辑的链接边,其关键变量有sourceVertex、targetVertex。
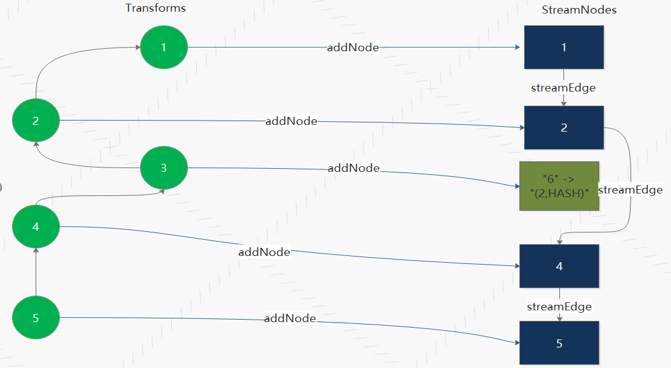
WindowWordCount transform 到 StreamGraph 转化如图所示, StreamExecutionEnvironment 的 transformations 存在 3 个 transform ,分别是 Flat Map(Id 2) 、 Window(Id 4) 、 Sink(Id 5) 。
transform 的时候首先递归处理 transform 的 input ,生成 StreamNode ,然后通过 StreamEdge 链接上下游 StreamNode 。需要注意的是,有些 transform 操作并不会生成 StreamNode 如 PartitionTransformtion ,而是生成个虚拟节点。
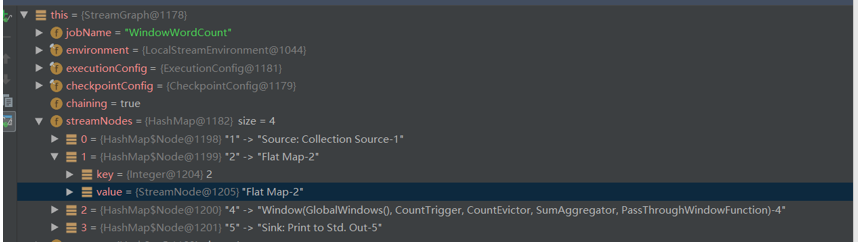
在转换完成后可以看到, streamNodes 有四种 transform 形式,分别为 Source 、 Flat Map 、 Window 、 Sink 。
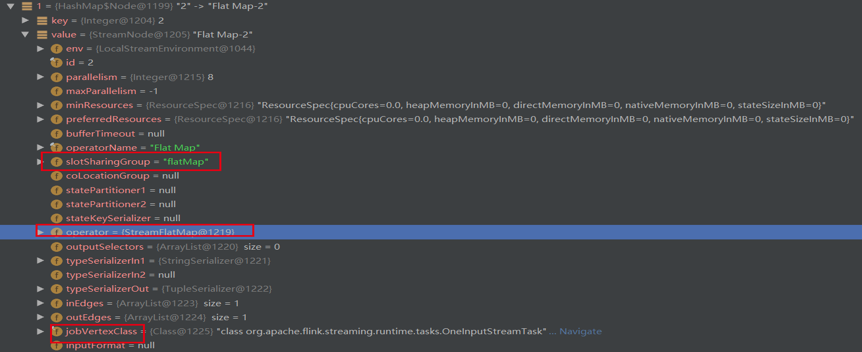
每个 streamNode 对象都携带并发个数、 slotSharingGroup 、执行类等运行信息。
1.2 StreamGraph 到 JobGraph 的转化¶
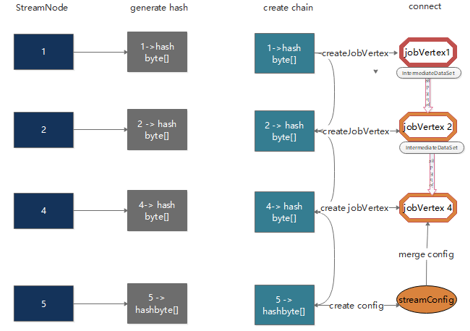
StreamGraph 到 JobGraph 的转化步骤:
-
设置调度模式,
Eager所有节点立即启动。 -
广度优先遍历
StreamGraph,为每个streamNode生成byte数组类型的hash值。 -
从
source节点开始递归寻找嵌到一起的operator,不能嵌到一起的节点单独生成jobVertex,能够嵌到一起的开始节点生成jobVertex,其他节点以序列化的形式写入到StreamConfig,然后merge到CHAINED_TASK_CONFIG,再通过JobEdge链接上下游JobVertex。 -
将每个
JobVertex的入边(StreamEdge)序列化到该StreamConfig。 -
根据
group name为每个JobVertext指定SlotSharingGroup。 -
配置
checkpoint。将缓存文件存文件的配置添加到configuration中。 -
设置
ExecutionConfig。
从 source 节点递归寻找嵌到一起的 operator 中,嵌到一起需要满足一定的条件,具体条件介绍如下:
-
下游节点只有一个输入。
-
下游节点的操作符不为
null。 -
上游节点的操作符不为
null。 -
上下游节点在一个槽位共享组内。
-
下游节点的连接策略是
ALWAYS。上游节点的连接策略是HEAD或者ALWAYS。 -
edge的分区函数是ForwardPartitioner的实例。 -
上下游节点的并行度相等。
-
可以进行节点连接操作。

JobGraph 对象结构如上图所示, taskVertices 中只存在 Window 、 Flat Map 、 Source 三个 TaskVertex , Sink operator 被嵌到 window operator 中去了。
1.2.1 为什么要为每个 operator 生成 hash 值?¶
Flink 任务失败的时候,各个 operator 是能够从 checkpoint 中恢复到失败之前的状态的,恢复的时候是依据 JobVertexID ( hash 值)进行状态恢复的。相同的任务在恢复的时候要求 operator 的 hash 值不变,因此能够获取对应的状态。
1.2.2 每个 operator 是怎样生成 hash 值的?¶
如果用户对节点指定了一个散列值,则基于用户指定的值能够产生一个长度为 16 的字节数组。如果用户没有指定,则根据当前节点所处的位置,产生一个散列值。
考虑的因素主要有三点:
-
一是在当前
StreamNode之前已经处理过的节点的个数,作为当前StreamNode的id,添加到hasher中; -
二是遍历当前
StreamNode输出的每个StreamEdge,并判断当前StreamNode与这个StreamEdge的目标StreamNode是否可以进行链接,如果可以,则将目标StreamNode的id也放入hasher中,且这个目标StreamNode的id与当前StreamNode的id取相同的值; -
三是将上述步骤后产生的字节数据,与当前
StreamNode的所有输入StreamNode对应的字节数据,进行相应的位操作,最终得到的字节数据,就是当前StreamNode对应的长度为16的字节数组。
1.3 JobGraph 到 ExecutionGraph 以及物理执行计划¶
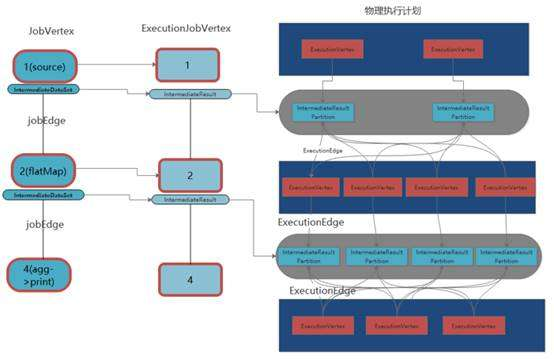
JobGraph 到 ExecutionGraph 以及物理执行计划的流程:
-
将
JobGraph里面的jobVertex从Source节点开始排序。 -
在
executionGraph.attachJobGraph(sortedTopology)方法里面,根据JobVertex生成ExecutionJobVertex,在ExecutionJobVertex构造方法里面,根据jobVertex的IntermediateDataSet构建IntermediateResult,根据jobVertex并发构建ExecutionVertex,ExecutionVertex构建的时候,构建IntermediateResultPartition(每一个Execution构建IntermediateResult数个IntermediateResultPartition);将创建的ExecutionJobVertex与前置的IntermediateResult连接起来。 -
构建
ExecutionEdge,连接到前面的IntermediateResultPartition,最终从ExecutionGraph到物理执行计划。
2 Flink Job 执行流程¶
2.1 Flink On Yarn 模式¶
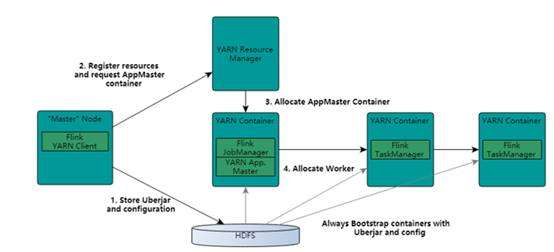
基于 Yarn 层面的架构类似 Spark on Yarn 模式,都是由 Client 提交 App 到 RM 上面去运行,然后 RM 分配第一个 container 去运行 AM ,然后由 AM 去负责资源的监督和管理。需要说明的是, Flink 的 Yarn 模式更加类似 Spark on Yarn 的 cluster 模式,在 cluster 模式中, dirver 将作为 AM 中的一个线程去运行。 Flink on Yarn 模式也是会将 JobManager 启动在 container 里面,去做个 driver 类似的任务调度和分配, Yarn AM 与 Flink JobManager 在同一个 Container 中,这样 AM 可以知道 Flink JobManager 的地址,从而 AM 可以申请 Container 去启动 Flink TaskManager 。待 Flink 成功运行在 Yarn 集群上, Flink Yarn Client 就可以提交 Flink Job 到 Flink JobManager ,并进行后续的映射、调度和计算处理。
2.1.1 Fink on Yarn 的缺陷¶
-
资源分配是静态的,一个作业需要在启动时获取所需的资源并且在它的生命周期里一直持有这些资源。这导致了作业不能随负载变化而动态调整,在负载下降时无法归还空闲的资源,在负载上升时也无法动态扩展。
-
On-Yarn模式下,所有的container都是固定大小的,导致无法根据作业需求来调整container的结构。譬如CPU密集的作业或许需要更多的核,但不需要太多内存,固定结构的container会导致内存被浪费。 -
与容器管理基础设施的交互比较笨拙,需要两个步骤来启动
Flink作业:-
启动
Flink守护进程; -
提交作业。如果作业被容器化并且将作业部署作为容器部署的一部分,那么将不再需要步骤
2。
-
-
On-Yarn模式下,作业管理页面会在作业完成后消失不可访问。Flink推荐
在 Flink 版本 1.5 中引入了 Dispatcher , Dispatcher 是在新设计里引入的一个新概念。 Dispatcher 会从 Client 端接受作业提交请求并代表它在集群管理器上启动作业。
2.1.2 引入 Dispatcher 的原因主要有两点¶
-
第一,一些集群管理器需要一个中心化的作业生成和监控实例;
-
第二,能够实现
Standalone模式下JobManager的角色,且等待作业提交。在一些案例中,Dispatcher是可选的(Yarn)或者不兼容的(kubernetes)。
2.2 资源调度模型重构下的 Flink On Yarn 模式¶
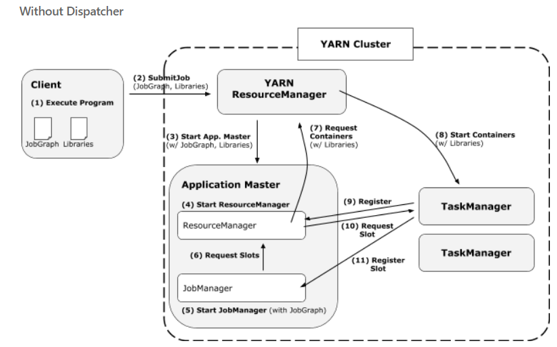
2.2.1 没有 Dispatcher job 运行过程¶
客户端提交 JobGraph 以及依赖 jar 包到 YarnResourceManager ,接着 Yarn ResourceManager 分配第一个 container 以此来启动 AppMaster , Application Master 中会启动一个 FlinkResourceManager 以及 JobManager , JobManager 会根据 JobGraph 生成的 ExecutionGraph 以及物理执行计划向 FlinkResourceManager 申请 slot , FlinkResoourceManager 会管理这些 slot 以及请求,如果没有可用 slot 就向 Yarn 的 ResourceManager 申请 container , container 启动以后会注册到 FlinkResourceManager ,最后 JobManager 会将 subTask deploy 到对应 container 的 slot 中去。
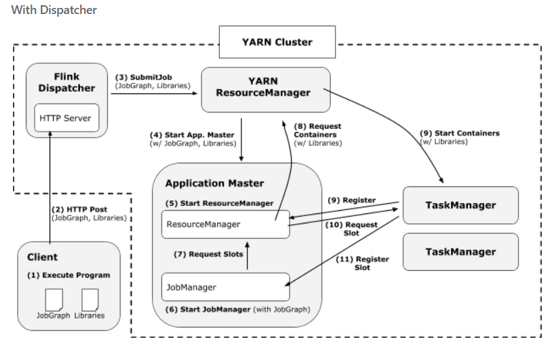
2.2.2 在有 Dispatcher 的模式下¶
会增加一个过程,就是 Client 会直接通过 HTTP Server 的方式,然后用 Dispatcher 将这个任务提交到 Yarn ResourceManager 中。
新框架具有四大优势,详情如下:
-
client直接在Yarn上启动作业,而不需要先启动一个集群然后再提交作业到集群。因此client再提交作业后可以马上返回。 -
所有的用户依赖库和配置文件都被直接放在应用的
classpath,而不是用动态的用户代码classloader去加载。 -
container在需要时才请求,不再使用时会被释放。 -
“需要时申请”的
container分配方式允许不同算子使用不同profile(CPU和内存结构)的container。
2.3 新的资源调度框架下 single cluster job on Yarn 流程介绍¶
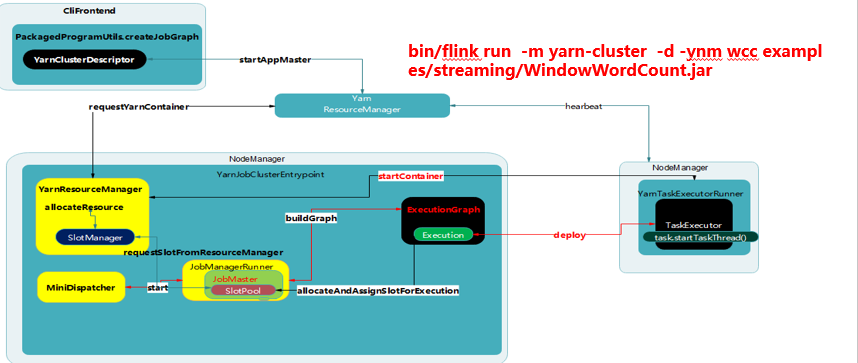
single cluster job on Yarn 模式涉及三个实例对象:
-
clifrontend -
Invoke App code; -
生成
StreamGraph,然后转化为JobGraph; -
YarnJobClusterEntrypoint(Master) -
依次启动
YarnResourceManager、MinDispatcher、JobManagerRunner三者都服从分布式协同一致的策略; -
JobManagerRunner将JobGraph转化为ExecutionGraph,然后转化为物理执行任务Execution,然后进行deploy,deploy过程会向YarnResourceManager请求slot,如果有直接deploy到对应的YarnTaskExecutiontor的slot里面,没有则向Yarn的ResourceManager申请,带container启动以后deploy。 -
YarnTaskExecutorRunner(slave) -
负责接收
subTask,并运行。
整个任务运行代码调用流程如下图:
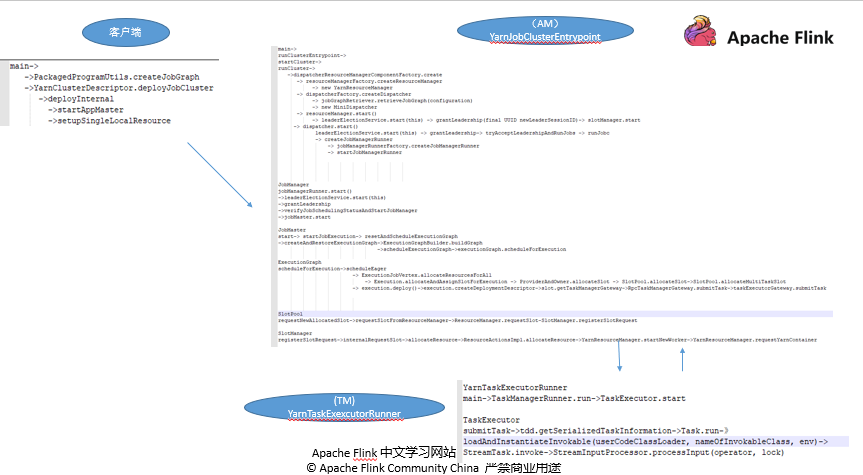
2.4 subTask 在执行时是怎么运行的?¶
| Bash | |
|---|---|
1 2 3 4 | |
我们来看下 flatMap 对应的 OneInputStreamTask 的 run 方法具体是怎么处理的。
| Java | |
|---|---|
1 2 3 4 5 6 7 8 | |
最终是调用 StreamInputProcessor 的 processInput() 做数据的处理,这里面包含用户的处理逻辑。
| Java | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | |
streamOperator.processElement(record) 最终会调用用户的代码处理逻辑,假如 operator 是 StreamFlatMap 的话,
| Java | |
|---|---|
1 2 3 4 5 | |