Apache Flink 零基础入门(3):开发环境搭建和应用的配置、部署及运行¶
1 Flink 开发环境部署和配置¶
Flink 是一个以 Java 及 Scala 作为开发语言的开源大数据项目,代码开源在 GitHub 上,并使用 Maven 来编译和构建项目。对于大部分使用 Flink 的同学来说, Java 、 Maven 和 Git 这三个工具是必不可少的,另外一个强大的 IDE 有助于我们更快的阅读代码、开发新功能以及修复 Bug 。因为篇幅所限,我们不会详述每个工具的安装细节,但会给出必要的安装建议。
关于开发测试环境, Mac OS 、 Linux 系统或者 Windows 都可以。如果使用的是 Windows 10 系统,建议使用 Windows 10 系统的 Linux 子系统来编译和运行。
建议选用社区已发布的稳定分支,比如 Release-1.6 或者 Release-1.7 。
1.1 编译 Flink 代码¶
在我们配置好之前的几个工具后,编译 Flink 就非常简单了,执行如下命令即可:
| Bash | |
|---|---|
1 2 3 | |
常用编译参数:
| Bash | |
|---|---|
1 2 3 | |
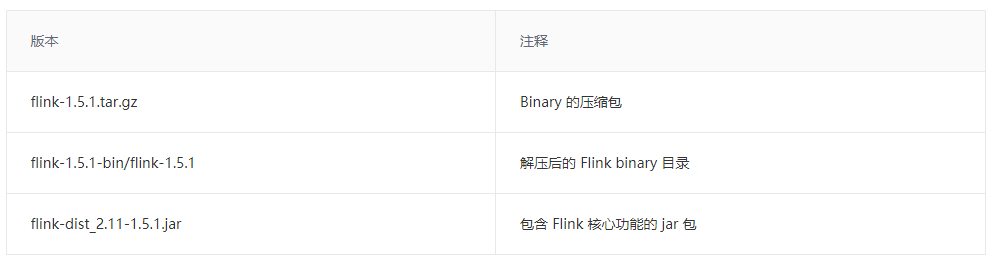
当成功编译完成后,能在当前 Flink 代码目录下的 flink-dist/target/子目录 中看到如下文件(不同的 Flink 代码分支编译出的版本号不同,这里的版本号是 Flink 1.5.1 ):

其中有三个文件可以留意一下:
注意:国内用户在编译时可能遇到编译失败 Build Failure (且有 MapR 相关报错),一般都和 MapR 相关依赖的下载失败有关,即使使用了推荐的 settings.xml 配置(其中 Aliyun Maven 源专门为 MapR 相关依赖做了代理),还是可能出现下载失败的情况。问题主要和 MapR 的 Jar 包比较大有关。遇到这些问题时,重试即可。在重试之前,要先根据失败信息删除 Maven local repository 中对应的目录,否则需要等待 Maven 下载的超时时间才能再次出发下载依赖到本地。
1.2 开发环境准备¶
推荐使用 IntelliJ IDEA IDE 作为 Flink 的 IDE 工具。官方不建议使用 Eclipse IDE ,主要原因是 Eclipse 的 Scala IDE 和 Flink 用 Scala 的不兼容。如果你需要做一些 Flink 代码的开发工作,则需要根据 Flink 代码的 tools/maven/目录 下的配置文件来配置 Checkstyle ,因为 Flink 在编译时会强制代码风格的检查,如果代码风格不符合规范,可能会直接编译失败。
2 运行 Flink 应用¶
2.1 基本概念¶
运行 Flink 应用其实非常简单,但是在运行 Flink 应用之前,还是有必要了解 Flink 运行时的各个组件,因为这涉及到 Flink 应用的配置问题。 图 1 所示,这是用户用 DataStream API 写的一个数据处理程序。可以看到,在一个 DAG 图中不能被 Chain 在一起的 Operator 会被分隔到不同的 Task 中,也就是说 Task 是 Flink 中资源调度的最小单位。

如下图 图 2 所示, Flink 实际运行时包括两类进程:
-
JobManager(又称为JobMaster):协调Task的分布式执行,包括调度Task、协调创Checkpoint以及当Job failover时协调各个Task从Checkpoint恢复等。 -
TaskManager(又称为Worker):执行Dataflow中的Tasks,包括内存Buffer的分配、Data Stream的传递等。
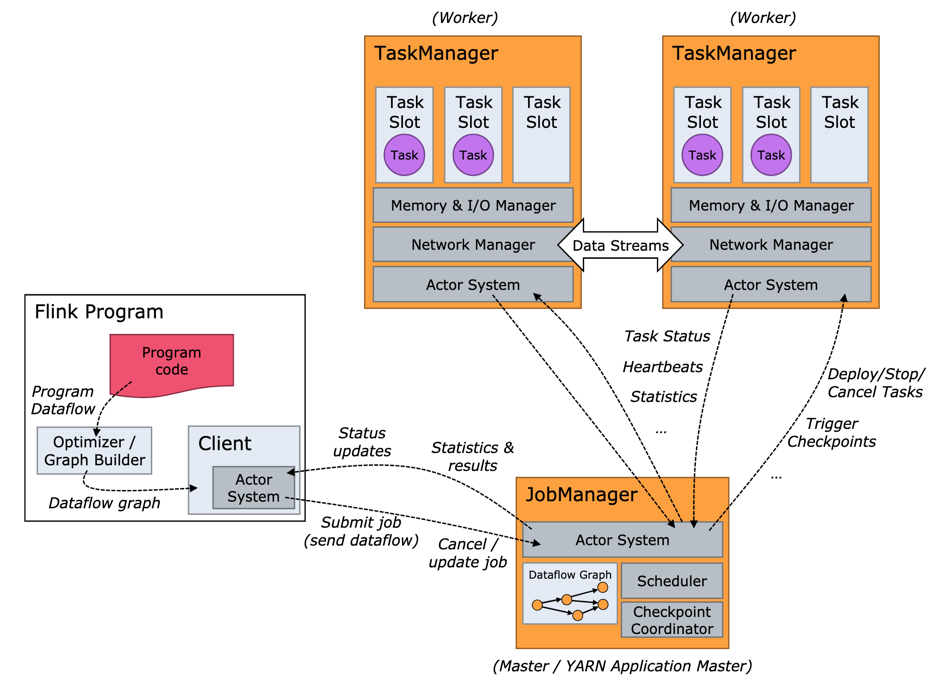
图 3 所示, Task Slot 是一个 TaskManager 中的最小资源分配单位,一个 TaskManager 中有多少个 Task Slot 就意味着能支持多少并发的 Task 处理。需要注意的是,一个 Task Slot 中可以执行多个 Operator ,一般这些 Operator 是能被 Chain 在一起处理的。

2.2 运行环境准备¶
-
准备
Flink binary -
直接从
Flink官网上下载Flink binary的压缩包 -
或者从
Flink源码编译而来 -
安装
Java,并配置JAVA_HOME环境变量
2.3 单机 Standalone 的方式运行 Flink¶
2.3.1 基本的启动流程¶
最简单的运行 Flink 应用的方法就是以单机 Standalone 的方式运行。
启动集群:
| Bash | |
|---|---|
1 | |
打开 http://127.0.0.1:8081/ 就能看到 Flink 的 Web 界面。尝试提交 Word Count 任务:
| Bash | |
|---|---|
1 | |
大家可以自行探索 Web 界面中展示的信息,比如,我们可以看看 TaskManager 的 stdout 日志,就可以看到 Word Count 的计算结果。我们还可以尝试通过 -input 参数指定我们自己的本地文件作为输入,然后执行:
| Bash | |
|---|---|
1 | |
停止集群:
| Bash | |
|---|---|
1 | |
2.3.2 常用配置介绍¶
-
这种方式太过底层,不够直观,我们还需要在此之上实现可视化展示;
-
系统表只记录了
CH自己的运行指标,有些时候我们需要外部系统的指标进行关联分析,例如ZooKeeper、服务器CPU、IO等等。 -
conf / slavesconf / slaves用于配置TaskManager的部署,默认配置下只会启动一个TaskManager进程,如果想增加一个TaskManager进程的,只需要文件中追加一行localhost。也可以直接通过
./bin/taskmanager.sh start这个命令来追加一个新的TaskManager:Bash 1./bin/taskmanager.sh start|start-foreground|stop|stop-all -
conf/flink-conf.yamlconf/flink-conf.yaml用于配置JM和TM的运行参数,常用配置有:Bash 1 2 3 4 5 6 7
## The heap size for the JobManager JVM jobmanager.heap.mb: 1024 ## The heap size for the TaskManager JVM taskmanager.heap.mb: 1024 ## The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: 4 ## the managed memory size for each task manager.
Standalone 集群启动后,我们可以尝试分析一下 Flink 相关进程的运行情况。执行 jps 命令,可以看到 Flink 相关的进程主要有两个,一个是 JobManager 进程,另一个是 TaskManager 进程。我们可以进一步用 ps 命令看看进程的启动参数中 -Xmx 和 -Xms 的配置。然后我们可以尝试修改 flink-conf.yaml 中若干配置,然后重启 Standalone 集群看看发生了什么变化。
需要补充的是,在 Blink 开源分支上, TaskManager 的内存计算上相对于现在的社区版本要更精细化, TaskManager 进程的堆内存限制( -Xmx )一般的计算方法是:
| Bash | |
|---|---|
1 | |
而最新的 Flink 社区版本 Release-1.7 中 JobManager 和 TaskManager 默认内存配置方式为:
| Bash | |
|---|---|
1 2 3 4 | |
Flink 社区 Release-1.7 版本中的 taskmanager.heap.size 配置实际上指的不是 Java heap 的内存限制,而是 TaskManager 进程总的内存限制。我们可以同样用上述方法查看 Release-1.7 版本的 Flink binary 启动的 TaskManager 进程的 -Xmx 配置,会发现实际进程上的 -Xmx 要小于配置的 taskmanager.heap.size 的值,原因在于从中扣除了 Network buffer 用的内存,因为 Network buffer 用的内存一定是 Direct memory ,所以不应该算在堆内存限制中。
2.3.3 日志的查看和配置¶
JobManager 和 TaskManager 的启动日志可以在 Flink binary 目录下的 Log 子目录中找到。 Log 目录中以 flink-{id}-${hostname} 为前缀的文件对应的是 JobManager 的输出,其中有三个文件:
-
flink-${user}-standalonesession-${id}-${hostname}.log:代码中的日志输出 -
flink-${user}-standalonesession-${id}-${hostname}.out:进程执行时的stdout输出 -
flink-${user}-standalonesession-${id}-${hostname}-gc.log:JVM的GC的日志
Log 目录中以 flink-{id}-${hostname} 为前缀的文件对应的是 TaskManager 的输出,也包括三个文件,和 JobManager 的输出一致。
日志的配置文件在 Flink binary 目录的 conf 子目录下,其中:
-
log4j-cli.properties:用Flink命令行时用的log配置,比如执行flink run命令 -
log4j-yarn-session.properties:用yarn-session.sh启动时命令行执行时用的log配置 -
log4j.properties:无论是Standalone还是Yarn模式,JobManager和TaskManager上用的log配置都是log4j.properties
这三个 log4j.*properties 文件分别有三个 logback.*xml 文件与之对应,如果想使用 Logback 的同学,之需要把与之对应的 log4j.*properties 文件删掉即可,对应关系如下:
-
log4j-cli.properties -> logback-console.xml -
log4j-yarn-session.properties -> logback-yarn.xml -
log4j.properties -> logback.xml
需要注意的是, flink-{id}-和{user}-taskexecutor-{hostname} 都带有 {id} 表示本进程在本机上该角色( JobManager 或 TaskManager )的所有进程中的启动顺序,默认从 0 开始。
2.3.4 进一步探索¶
尝试重复执行 ./bin/start-cluster.sh 命令,然后看看 Web 页面(或者执行 jps 命令),看看会发生什么?可以尝试看看启动脚本,分析一下原因。接着可以重复执行 ./bin/stop-cluster.sh ,每次执行完后,看看会发生什么。
2.4 多机部署 Flink Standalone 集群¶
部署前要注意的要点:
-
每台机器上配置好
Java以及JAVA_HOME环境变量 -
每台机器上部署的
Flink binary的目录要保证是同一个目录 -
如果需要用
HDFS,需要配置HADOOP_CONF_DIR环境变量配置
根据你的集群信息修改 conf/masters 和 conf/slaves 配置。
修改 conf/flink-conf.yaml 配置,注意要确保和 Masters 文件中的地址一致:
| Bash | |
|---|---|
1 | |
确保所有机器的 Flink binary 目录中 conf 中的配置文件相同,特别是以下三个:
| Bash | |
|---|---|
1 2 3 | |
然后启动 Flink 集群:
| Bash | |
|---|---|
1 | |
提交 WordCount 作业:
| Bash | |
|---|---|
1 | |
上传 WordCount 的 Input 文件:
| Bash | |
|---|---|
1 | |
提交读写 HDFS 的 WordCount 作业:
| Bash | |
|---|---|
1 | |
增加 WordCount 作业的并发度(注意输出文件重名会提交失败):
| Bash | |
|---|---|
1 | |
2.5 Standalone 模式的 HighAvailability(HA)部署和配置¶
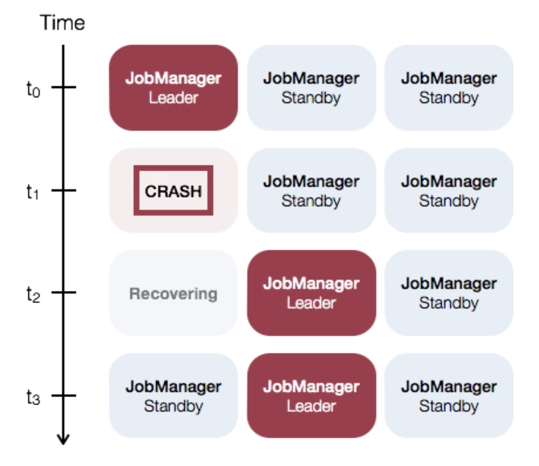
通过 图 2 Flink Runtime 架构图 ,我们可以看到 JobManager 是整个系统中最可能导致系统不可用的角色。如果一个 TaskManager 挂了,在资源足够的情况下,只需要把相关 Task 调度到其他空闲 TaskSlot 上,然后 Job 从 Checkpoint 中恢复即可。而如果当前集群中只配置了一个 JobManager ,则一旦 JobManager 挂了,就必须等待这个 JobManager 重新恢复,如果恢复时间过长,就可能导致整个 Job 失败。
因此如果在生产业务使用 Standalone 模式,则需要部署配置 HighAvailability ,这样同时可以有多个 JobManager 待命,从而使得 JobManager 能够持续服务。
注意:
-
如果想使用
Flink standalone HA模式,需要确保基于Flink Release-1.6.1及以上版本,因为这里社区有个bug会导致这个模式下主JobManager不能正常工作。 -
接下来的实验中需要用到
HDFS,所以需要下载带有Hadoop支持的Flink Binary包。
2.5.1 (可选)使用 Flink 自带的脚本部署 ZK¶
Flink 目前支持基于 Zookeeper 的 HA 。如果你的集群中没有部署 ZK , Flink 提供了启动 Zookeeper 集群的脚本。首先修改配置文件 conf/zoo.cfg ,根据你要部署的 Zookeeper Server 的机器数来配置 server.X=addressX:peerPort:leaderPort ,其中 X 是一个 Zookeeper Server 的唯一 ID ,且必须是数字。
| Bash | |
|---|---|
1 2 3 4 5 | |
然后启动 Zookeeper :
| Bash | |
|---|---|
1 | |
jps 命令看到 ZK 进程已经启动:
停掉 Zookeeper 集群的命令:
| Bash | |
|---|---|
1 | |
2.5.2 修改 Flink Standalone 集群的配置¶
修改 conf/masters 文件,增加一个 JobManager :
| Bash | |
|---|---|
1 2 3 | |
之前修改过的 conf/slaves 文件保持不变:
| Bash | |
|---|---|
1 2 3 4 | |
修改 conf/flink-conf.yaml 文件:
| Bash | |
|---|---|
1 2 3 4 5 6 7 8 9 10 | |
需要注意的是,在 HA 模式下 conf/flink-conf.yaml 中的这两个配置都失效了(想想为什么)。
| Bash | |
|---|---|
1 | |
修改完成后,确保配置同步到其他机器。
启动 Zookeeper 集群:
| Bash | |
|---|---|
1 | |
再启动 Standalone 集群(要确保之前的 Standalone 集群已经停掉):
| Bash | |
|---|---|
1 | |
分别打开两个 Master 节点上的 JobManager Web 页面:
http://z05f06378.sqa.zth.tbsite.net:8081
http://z05c19426.sqa.zth.tbsite.net:8081
可以看到两个页面最后都转到了同一个地址上,这个地址就是当前主 JobManager 所在机器,另一个就是 Standby JobManager 。以上我们就完成了 Standalone 模式下 HA 的配置。
接下来我们可以测试验证 HA 的有效性。当我们知道主 JobManager 的机器后,我们可以把主 JobManager 进程 Kill 掉,比如当前主 JobManager 在 z05c19426.sqa.zth.tbsite.net 这个机器上,就把这个进程杀掉。
接着,再打开这两个链接: http://z05f06378.sqa.zth.tbsite.net:8081 http://z05c19426.sqa.zth.tbsite.net:8081
可以发现后一个链接已经不能展示了,而前一个链接可以展示,说明发生主备切换。然后我们再重启前一次的主 JobManager :
| Bash | |
|---|---|
1 | |
再打开 http://z05c19426.sqa.zth.tbsite.net:8081 这个链接,会发现现在这个链接可以转到 http://z05f06378.sqa.zth.tbsite.net:8081 这个页面上了。说明这个 JobManager 完成了一个 Failover Recovery 。
2.6 使用 Yarn 模式跑 Flink job¶
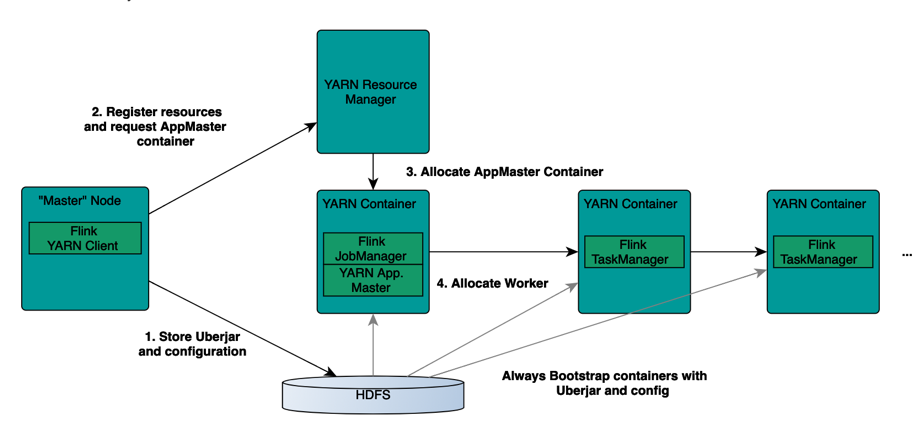
相对于 Standalone 模式, Yarn 模式允许 Flink job 的好处有:
-
资源按需使用,提高集群的资源利用率
-
任务有优先级,根据优先级运行作业
-
基于
Yarn调度系统,能够自动化地处理各个角色的Failover -
JobManager进程和TaskManager进程都由Yarn NodeManager监控 -
如果
JobManager进程异常退出,则Yarn ResourceManager会重新调度JobManager到其他机器 -
如果
TaskManager进程异常退出,JobManager会收到消息并重新向Yarn ResourceManager申请资源,重新启动TaskManager
2.6.1 在 Yarn 上启动 Long Running 的 Flink 集群(Session Cluster 模式)¶
查看命令参数:
| Bash | |
|---|---|
1 | |
创建一个 Yarn 模式的 Flink 集群:
| Bash | |
|---|---|
1 | |
其中用到的参数是:
-
-n,-container Number of TaskManagers -
-jm,-jobManagerMemory Memory for JobManager Container with optional unit (default: MB) -
-tm,-taskManagerMemory Memory per TaskManager Container with optional unit (default: MB) -
-qu,-queue Specify YARN queue. -
-s,-slots Number of slots per TaskManager -
-t,-ship Ship files in the specified directory (t for transfer)
提交一个 Flink job 到 Flink 集群:
| Bash | |
|---|---|
1 | |
这次提交 Flink job ,虽然没有指定对应 Yarn application 的信息,却可以提交到对应的 Flink 集群,原因在于 /tmp/.yarn-properties-${user} 文件中保存了上一次创建 Yarn session 的集群信息。所以如果同一用户在同一机器上再次创建一个 Yarn session ,则这个文件会被覆盖掉。
-
如果删掉
/tmp/.yarn-properties-${user}或者在另一个机器上提交作业能否提交到预期到yarn session中呢?可以配置了high-availability.cluster-id参数,据此从Zookeeper上获取到JobManager的地址和端口,从而提交作业。 -
如果
Yarn session没有配置HA,又该如何提交呢?
这个时候就必须要在提交 Flink job 的命令中指明 Yarn 上的 Application ID ,通过 -yid 参数传入:
| Bash | |
|---|---|
1 | |
我们可以发现,每次跑完任务不久, TaskManager 就被释放了,下次在提交任务的时候, TaskManager 又会重新拉起来。如果希望延长空闲 TaskManager 的超时时间,可以在 conf/flink-conf.yaml 文件中配置下面这个参数,单位是 milliseconds :
| Bash | |
|---|---|
1 2 | |
2.6.2 在 Yarn 上运行单个 Flink job(Job Cluster 模式)¶
如果你只想运行单个 Flink Job 后就退出,那么可以用下面这个命令:
| Bash | |
|---|---|
1 | |
常用的配置有:
-
-yn,-yarncontainer Number of Task Managers -
-yqu,-yarnqueue Specify YARN queue. -
-ys,-yarnslots Number of slots per TaskManager -
-yqu,-yarnqueue Specify YARN queue.
可以通过 Help 命令查看 Run 的可用参数:
| Bash | |
|---|---|
1 | |
我们可以看到, ./bin/flink run -h 看到的 Options for yarn-cluster mode 中的 -y 和 -yarn 为前缀的参数其实和 ./bin/yarn-session.sh -h 命令是一一对应的,语义上也基本一致。
关于 -n (在 yarn session 模式下)、 -yn 在( yarn single job 模式下)与 -p 参数的关系:
-
-n和-yn在社区版本中(Release-1.5~Release-1.7)中没有实际的控制作用,实际的资源是根据-p参数来申请的,并且TM使用完后就会归还 -
在
Blink的开源版本中,-n(在Yarn Session模式下)的作用就是一开始启动指定数量的TaskManager,之后即使Job需要更多的Slot,也不会申请新的TaskManager -
在
Blink的开源版本中,Yarn single job模式-yn表示的是初始TaskManager的数量,不设置TaskManager的上限。(需要特别注意的是,只有加上-yd参数才能用Single job模式(例如:命令./bin/flink run -yd -m yarn-cluster xxx)
2.7 Yarn 模式下的 HighAvailability 配置¶
首先要确保启动 Yarn 集群用的 yarn-site.xml 文件中的这个配置,这个是 Yarn 集群级别 AM 重启的上限。
| Bash | |
|---|---|
1 2 3 4 | |
然后在 conf/flink-conf.yaml 文件中配置这个 Flink job 的 JobManager 能够重启的次数。
| Bash | |
|---|---|
1 | |
最后再在 conf/flink-conf.yaml 文件中配置上 ZK 相关配置,这几个配置的配置方法和 Standalone 的 HA 配置方法基本一致,如下所示。
| Bash | |
|---|---|
1 2 3 4 5 6 7 8 9 10 | |
需要特别注意的是: high-availability.cluster-id 这个配置最好去掉,因为在 Yarn (以及 Mesos )模式下, cluster-id 如果不配置的话,会配置成 Yarn 上的 Application ID ,从而可以保证唯一性。